

بدیهی است که هوش مصنوعی و یادگیری ماشین، از تأثیرگذارترین فناوریها در حوزۀ فناوری اطلاعات محسوب میشوند و مسیر توسعۀ سریع و شگرفی را طی کردهاند.
امیدوارم این مقاله بتواند گام بسیار کوچکی در مسیر بومیسازی این فناوری در کشور بردارد. ضمن اینکه میتوانید اصل مقاله را که به زبان انگلیسی نوشته شده است، از طریق لینک زیر مشاهده کنید:
https://vas3k.com/blog/machine_learning/
اگر تا به حال مقالاتی در مورد یادگیریِ ماشین در اینترنت خوانده باشید، بهاحتمال زیاد با دو نوع مختلف از آنها برخورد کردهاید: مقالههای حجیم و آکادمیک که پر از تئوریهای مختلف است(این مقالات آنقدر ثقیل هستند که حتی نیمی از یکی از آنها را هم نمیتوانیم بخوانیم) و نوع دوم داستانهای تخیلی دربارۀ هوش مصنوعی، دادهها، جادوی علم و مشاغل آینده است.
من تصمیم گرفتم متنی را بنویسم که مدتها آرزو داشتم وجود داشته باشد. مقالهای با یک مقدمهی ساده برای کسانی که همیشه میخواستند «یادگیری ماشین» را بفهمند. مقالهای که فقط شامل مسائل موجود در دنیای واقعی و با راهحلهای عملی بوده و با زبانی ساده و بدون قضیههای سطح بالا و آکادمیک نوشته شده باشد. یک مقاله برای همهی افراد با سطوح مختلف از برنامهنویسها گرفته تا مدیران.

[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]
چرا میخواهیم ماشینها یاد بگیرند؟
این بیلی است. بیلی میخواهد ماشین بخرد. او تلاش میکند که بفهمد ماهانه چقدر باید برای خرید یک ماشین پسانداز کند. او دهها آگهی را در اینترنت دیده و متوجه شده است که قیمت خودروهای نو حدود ۲۰۰۰۰ دلار، خودروهای دستهدومی که یکسال کار کردهاند ۱۹۰۰۰ دلار و ۲ سالهها ۱۸۰۰۰ دلار هستند و…
بیلی، تحلیلگر درخشان ما، متوجه یک الگو میشود: قیمت خودرو به سن آن بستگی دارد به طوری که به ازای هر سال کارکرد ۱۰۰۰ دلار از قیمت آن کاسته میشود، اما در هر صورت قیمت آن کمتر از ۱۰۰۰۰ دلار نخواهد شد.
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5436″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
در دنیای یادگیری ماشین، اصطلاحاً به کاری که بیلی انجام داد [dt_tooltip title=”رگرسیون”] Regression[/dt_tooltip] میگوییم. او یک ارزش (قیمت خودرو) را بر اساس دادههای تاریخیِ مشخصی پیشبینی کرد. عموم مردم همیشه این کار را انجام میدهند، مثلاً ممکن است تلاش کنند قیمت یک آیفون دستِ دوم را در فروشگاه eBay تخمین بزنند یا مثلاً بفهمند که برای یک مهمانی [dt_tooltip title=”باربیکیو”]منظور از مهمانی باربیکیو مهمانی است که در آن برای مهمانان کباب تهیه و سرو میشود.[/dt_tooltip] چقدر گوشتِ راسته باید بخرند. ۲۰۰ گرم برای هر نفر؟ ۵۰۰گرم؟
بله! خوب است که برای هر مشکلی در جهان مثل مهمانی باربیکیو یک فرمول ساده داشته باشیم. ولی متأسفانه در عمل اینکار غیرممکن است.
دوباره به مثال خرید ماشینبرگردیم. مشکل اینجاست که علاوه بر تاریخ ساخت متفاوتی که ماشینها دارند، دهها گزینه(Option) و یا شرایط فنی متفاوتی دارند و حتی در فصلهایی از سال افزایش تقاضا دارند که بر روی قیمت آنها مؤثر است و خدا میداند چند عامل پنهان دیگر وجود دارد که بر روی قیمت خودرو تأثیر میگذارد. یک آدم معمولی مثل بیلی نمیتواند تمام این دادهها را در حین محاسبهی قیمت در ذهن خود نگه دارد. ما هم همینطور.
مردم معمولاً حوصلهی انجام این قبیل کارها را نداشته و تمایلی برای محاسبات و تحلیلهای اینچنینی و یا صرف وقت زیاد در این مسائل را ندارند. بنابراین، ما به رباتهایی نیاز داریم که این محاسبات و تحلیلها را برای مردم انجام دهند. حالا اجازه بدهید راه محاسباتی توسط رباتها را برویم. برای این منظور اطلاعاتی را به دستگاه ارائه دهیم و از آن بخواهیم همه الگوهای پنهان مربوط به قیمت را پیدا کند. آیا امکانپذیر است؟
بله! ماشین میتواند این کار را انجام دهد. اما بخش هیجانانگیز ماجرا این است که دستگاه این کار را بسیار بهتر از یک فرد واقعی انجام میدهد، بدین صورت که تمام وابستگیها را در ذهن خود تجزیه و تحلیل میکند.
این تولدِ یادگیری ماشین(یا همان ماشین لرنینگ) است!
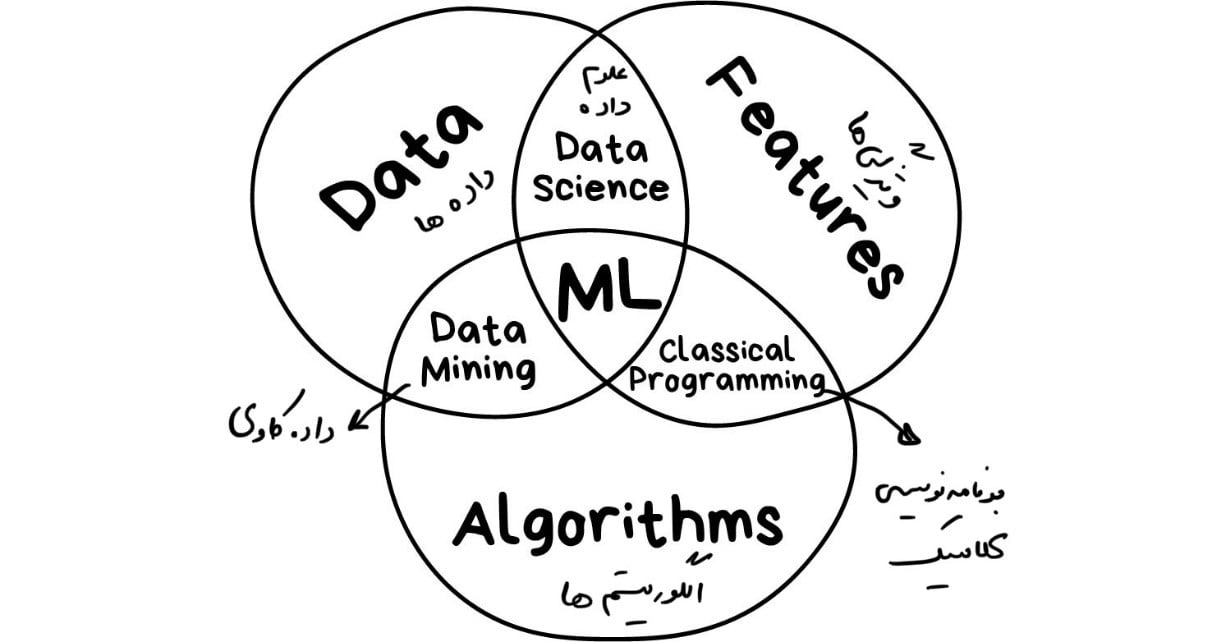
سه مؤلفهی اصلی در یادگیری ماشین
اگر حواشی و داستانهای ایجادشده در اطراف هوش مصنوعی را کنار بگذاریم، تنها هدف یادگیری ماشین پیشبینی نتایج بر اساس دادههای دریافتی است. همین! همهی آنچه که در یادگیری ماشین میگذرد را میتوان با این تعریف توضیح داد. مگر اینکه مسألهای که طرح کردهایم از ابتدا در حوزهی یادگیری ماشین نبوده باشد.
هرچه تنوع بیشتری در نمونهها(دادههای دریافتی) داشته باشید، پیدا کردن الگوهای مرتبط و پیشبینی نتیجه در آن آسانتر است. بنابراین برای آموزش ماشین به سه جزء نیاز داریم: ۱- دادهها ۲-ویژگیها ۳-الگوها
دادهها(Data)
آیا میخواهید پیامهای هرز و بلااستفاده را در صندوق پیامهای ورودی خود شناسایی کنید؟ برای این کار لازم است نمونههایی از پیامهای هرز و بلااستفاده([dt_tooltip title=”هرزنامه”]Spam Message[/dt_tooltip]) را مشخص و جمعآوری کنید.
آیا میخواهید ارزش سهام را پیشبینی کنید؟ باید تاریخچهی قیمت سهام را پیدا و جمعآوری کنید.
آیا میخواهید بدانید یک کاربر چهچیز را ترجیح میدهد؟ باید فعالیتهای آن کاربر را در فیسبوک تجزیه و تحلیل کنید (البته این کار رو به مارک زاکربرگ توصیه نمیکنم!) هر چه دادهها متنوعتر باشند، نتیجه بهتری حاصل میشود. جمعآوری دهها هزار ردیف از دادهها، یک عدد حداقلی برای کارهای بسیار پیشپا افتاده و ابتدائی است.
دو راه اصلی برای جمعآوری داده وجود دارد: دستی و خودکار. دادههای جمعآوریشده بهصورت دستی حاوی خطاهای بسیار کمتری هستند، اما جمعآوری آن نیاز به زمان بیشتری دارد، که به طور کلی آن را گرانتر میکند.
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]
رویکرد خودکار ارزانتر است. شما هر چیزی را که میتوانید پیدا کنید جمعآوری میکنید و امیدوارید که بهترین نمونهها برای شما پیدا شود.
برخی از سیستمهای هوشمند مانند گوگل از مشتریان خود برای برچسبگذاری رایگان دادهها استفاده میکنند. مثلاً اگر به reCAPTCHA دقت کرده باشید، شما را مجبور به “انتخاب همهی علائم خیابان” میکند! این دقیقاً همان جمعآوری و برچسبگذاری خودکاری است که این قبیل شرکتها انجام میدهند. کاملاً رایگان! خیلی هم خوب! ما هم میتوانیم همین کار را انجام دهیم و نشان دادن کپچا را بیشتر و بیشتر میکنیم. اما صبر کنید…
جمعآوری یک مجموعهی خوب از دادهها ([dt_tooltip title=”که معمولاً مجموعهداده”]Data Set[/dt_tooltip] نامیده میشود) بسیار دشوار است. این مجموعهدادهها آنقدر مهم هستند که شرکتها شاید الگوریتمهای خود را افشا کنند، اما بعید است مجموعهدادههای خود را به کسی نشان دهند.
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5438″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
ویژگیها (Features)
ویژگیها تحت عناوینی مانند [dt_tooltip title=”پارامترها”]Parameters[/dt_tooltip] یا [dt_tooltip title=”متغیرها”]Variables[/dt_tooltip] شناخته میشوند. این موارد میتواند مسافت پیموده شدهی خودرو، جنسیت کاربر، قیمت سهام یا فراوانی کلمه در متن باشد. به عبارت دیگر، اینها عواملی هستند که یک ماشین باید به آنها نگاه کند.
وقتی دادهها در جداول ذخیره میشوند، موضوع ساده است: ویژگیها همان نام ستونها هستند. اما اگر ۱۰۰ گیگابایت عکس از گربههای ملوس داشته باشید ویژگیها چه چیزی هستند؟ ما نمیتوانیم هر پیکسل را بهعنوان یک ویژگی در نظر بگیریم. بههمین دلیل است که انتخاب ویژگیهای مناسب معمولاً بیشتر از سایر بخشهای یادگیری ماشین طول میکشد. استخراج این ویژگیها یکی از منابع اصلی خطاها است. آدمها معمولاً محصور به ذهن خود هستند. یعنی فقط ویژگیهایی را انتخاب میکنند که دوست دارند یا “مهمتر” میدانند ولی در این موضوع بهتر است از این «ذهنی بودن» خودداری کنیم.
الگوریتمها
الگوریتمها واضحترین بخش ماشین لرنینگ هستند. هر مشکلی را میتوان با روشهای متفاوتی حل کرد. روشی که انتخاب میکنید بر دقت، کارایی و اندازهی مدلِ نهایی تأثیر میگذارد. با این حال یک نکتهی مهم وجود دارد: اگر دادهها نامرتب و مغشوش باشند، حتی بهترین الگوریتمها هم بهکار نمیآیند. گاهی اوقات از این حالت با اصطلاحِ “[dt_tooltip title=”اگه آشغال بِدی از توش آشغال در میاد!”]garbage in – garbage out[/dt_tooltip]” یاد میشود. پس زیاد به درصد دقت توجه نکنید. سعی کنید در وهلهی اول تا میتوانید دادههای بیشتری بهدست آورید.
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]
[dt_tooltip title=”
یادگیری یا هوشمندی
“] Intelligence[/dt_tooltip]؟ مسئله این است.
یکبار، مقالهای در یکی از وبسایتهای امروزی دیدم با عنوان “آیا شبکههای عصبی جایگزین یادگیری ماشین خواهند شد؟”. انگار این اهالی رسانه(مخصوصاً در Skynet) با خودشان قرار گذاشتهاند که به هر رگرسیون خطی کوچک و سادهای بگویند «هوش مصنوعی»! پس باید به تصویر زیر نگاه کنیم که جریان از چه قرار است.
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5445″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
[dt_tooltip title=”هوش مصنوعی”]Artificial Intelligence (AI)[/dt_tooltip] نام یک حوزهی دانش کامل و مستقل است؛ چیزی شبیه به زیستشناسی یا شیمی.
ماشین لِرنینگ بخشی از هوشِ مصنوعی است. بخش مهمی است، ولی همۀ آن نیست.
[dt_tooltip title=”شبکههای عصبی“]Neural Networks[/dt_tooltip] یکی از انواع یادگیری ماشین هستند. یک مورد محبوب، اما موارد مهم و خوب دیگری هم در این سطح هستند.
[dt_tooltip title=”یادگیری عمیق”]Deep Learning[/dt_tooltip] یک روش پیشرفته برای ساخت، آموزش و استفاده از شبکههای عصبی است. در اصل، یادگیری عمیق یک معماری جدید در شبکههای عصبی است. در حال حاضر، دیگر هیچکس یادگیری عمیق را از “شبکههای عصبی مرسوم” جدا نمیکند. حتی از همین کتابخانههای مرسوم برای پیادهسازی آن نیز استفاده میشود. برای جلوگیری از اشتباهات لفظی، بهتر است فقط نام شبکه را بگوئیم و از بهکاربردن سایر کلمات رایج و اشتباه خودداری کنیم.
قاعدهی کلی این است که اشیائی را با هم مقایسه کنیم که در یک سطح هستند. بههمین دلیل است که عبارت “آیا شبکههای عصبی جایگزین یادگیری ماشین خواهند شد؟” مثل عبارت “آیا چرخها جایگزین خودروها خواهند شد؟” بیمعنی به نظر میرسد. این قبیل رسانههای تبلیغاتی، آبروی شما را بسیار بهخطر میاندازند.
| ماشین میتواند | ماشین نمیتواند | |
| پیشبینی کند | چیز جدیدی ایجاد یا خلق کند | |
| بهخاطر بسپارد | خیلی سریع هوشمند شود | |
| باز تولید کند | فراتر از وظیفهی خودش برود | |
| بهترین مورد را انتخاب کند | همهی انسانها را بهقتل برساند! |
نقشهی دنیای یادگیریِ ماشین
اگر حوصلهی خواندن مطالب طولانی را ندارید، به تصویر زیر نگاه کنید تا کمی موضوع را درک کنید.
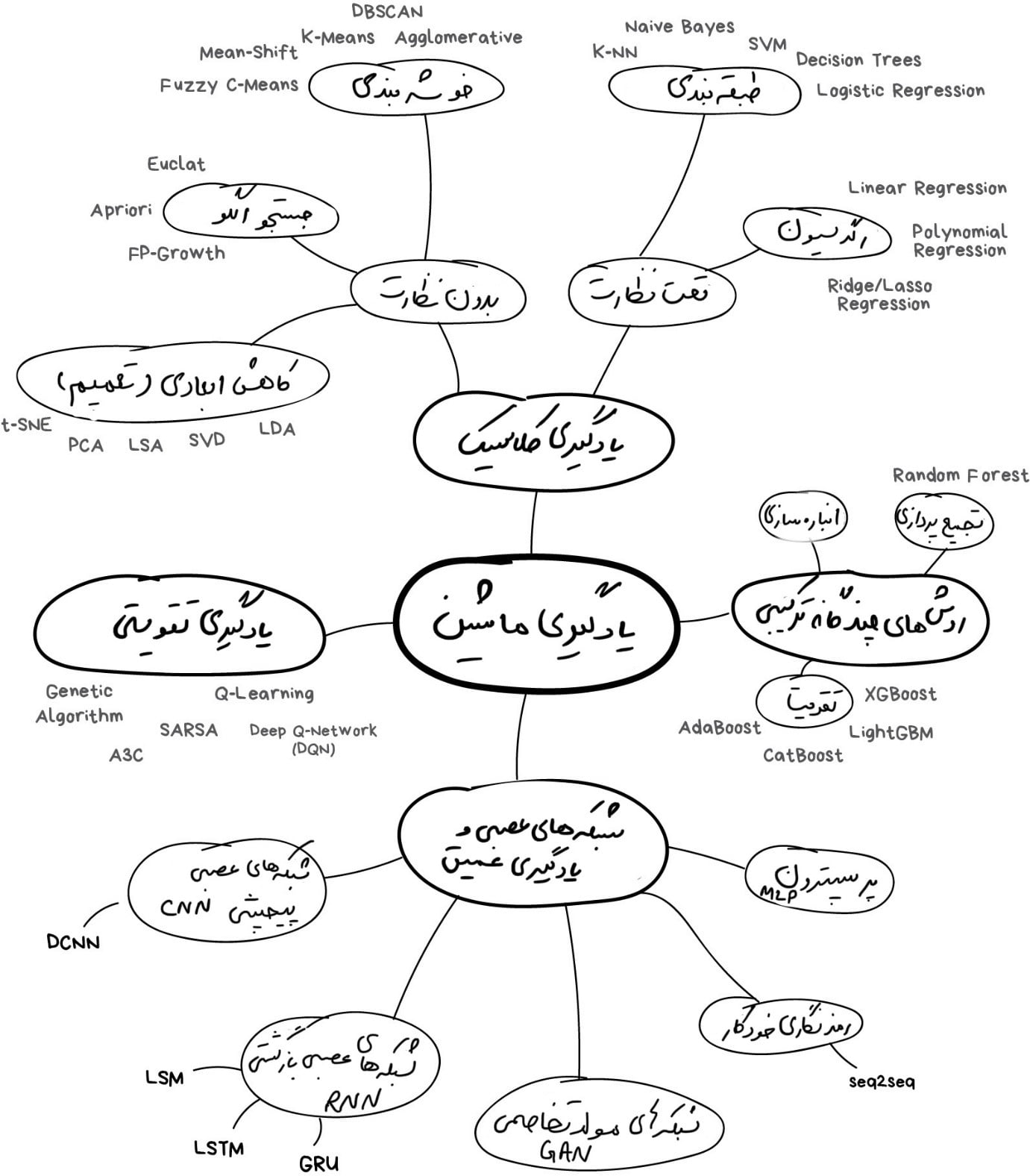 همیشه مهم است که یک نکته را به یاد داشته باشیم: هیچگاه برای حل یک مسأله در دنیای یادگیری ماشین، تنها یک راهحل وجود ندارد. همیشه چندین الگوریتم مناسب وجود دارد و شما باید انتخاب کنید که کدامیک از آنها بهتر است. البته همه چیز را میتوان با یک شبکهی عصبی حل کرد، اما چه کسی هزینهی اینهمه کارت گرافیکی GeForce را پرداخت میکند؟ (توضیح: شبکههای عصبی نیاز به منابع پردازشی زیادی دارند که معمولاً این کار با استفاده از کارتهای گرافیکی انجام میشود و این کارتهای گرافیکی به خاطر قدرت پردازش بالایی که دارند بسیار گرانقیمت هستند.)
همیشه مهم است که یک نکته را به یاد داشته باشیم: هیچگاه برای حل یک مسأله در دنیای یادگیری ماشین، تنها یک راهحل وجود ندارد. همیشه چندین الگوریتم مناسب وجود دارد و شما باید انتخاب کنید که کدامیک از آنها بهتر است. البته همه چیز را میتوان با یک شبکهی عصبی حل کرد، اما چه کسی هزینهی اینهمه کارت گرافیکی GeForce را پرداخت میکند؟ (توضیح: شبکههای عصبی نیاز به منابع پردازشی زیادی دارند که معمولاً این کار با استفاده از کارتهای گرافیکی انجام میشود و این کارتهای گرافیکی به خاطر قدرت پردازش بالایی که دارند بسیار گرانقیمت هستند.)
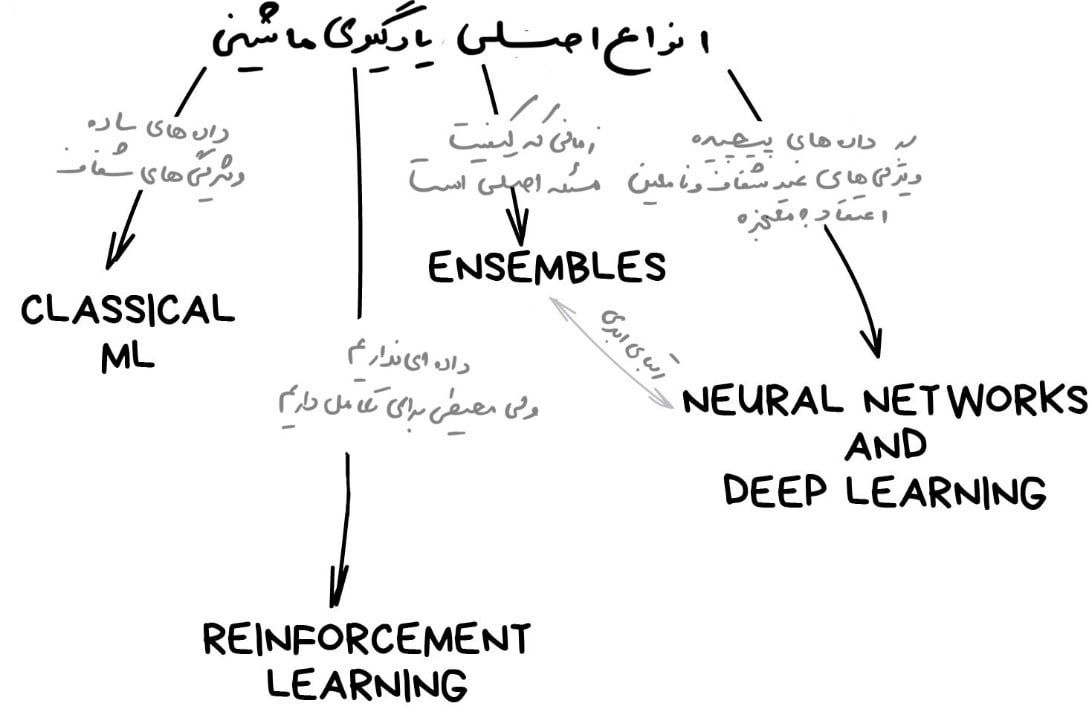
بیایید با یک مرور کلی شروع کنیم. امروزه چهار نوع یادگیری ماشین وجود دارد که این چهار نوع در شکل زیر نمایش داده شدهاند. در بخشهای بعدی هر یک از آنها را توضیح خواهیم داد.
بخش اول: [dt_tooltip title=”
ماشینلِرنینگِ کلاسیک
“]Classical Machine Learning[/dt_tooltip]
اولین روشهای یادگیری، از روشهای آماری خالص در دههی ۵۰ بهدست آمد. روشهایی که مسائل ریاضی عمومی را حل میکردند. مسایلی مانند جستجوی الگوها در اعداد، ارزیابی نزدیکی نقاط داده، و محاسبه جهت بردارها.
اما امروزه نیمی از اینترنت توسط این الگوریتمها کار میکنند. وقتی یک وبسایت فهرستی از مقالهها را که باید «بعداً بخوانید» به شما نشان میدهد یا بانک شما کارتتان را در یک پمپ بنزین در میانهی ناکجاآباد مسدود میکند، بهاحتمال زیاد کار کارِ یکی از همین الگوریتمها است.
شرکتهای بزرگ فناوری، از طرفداران بزرگ شبکههای عصبی هستند. به طور مشخص، برای آنها، افزایش دقت به میزان ۲ درصد، ۲ میلیارد درآمد اضافی را به ارمغان خواهد آورد. اما برای شرکتهای کوچک، این میزان از دقت توجیه منطقی و اقتصادی ندارد. داستانهای مختلفی در اینباره وجود دارد: بهعنوان مثال برخی از تیمها یک سال مداوم را روی یک الگوریتم جدید برای وبسایت تجارت الکترونیک خود صرف میکردند، در حالی که ۹۹درصد ترافیک از موتورهای جستجو میآمدند! یعنی این الگوریتمها تاثیر چندانی بر نتیجه نداشتند و تقریباً بیفایده بودند. اکثر کاربران، صفحه اصلی را اصلاً باز نمیکردند!
برخلاف چیزی که شایع شده است، رویکردهای کلاسیک آنقدر طبیعی هستند که حتی میتوان آنها را به راحتی برای کودکان نیز توضیح داد. رویکردهای کلاسیک مانند محاسبات ابتدائی هستند. ما هر روز از آن استفاده میکنیم، بدون اینکه حتی فکر کنیم.
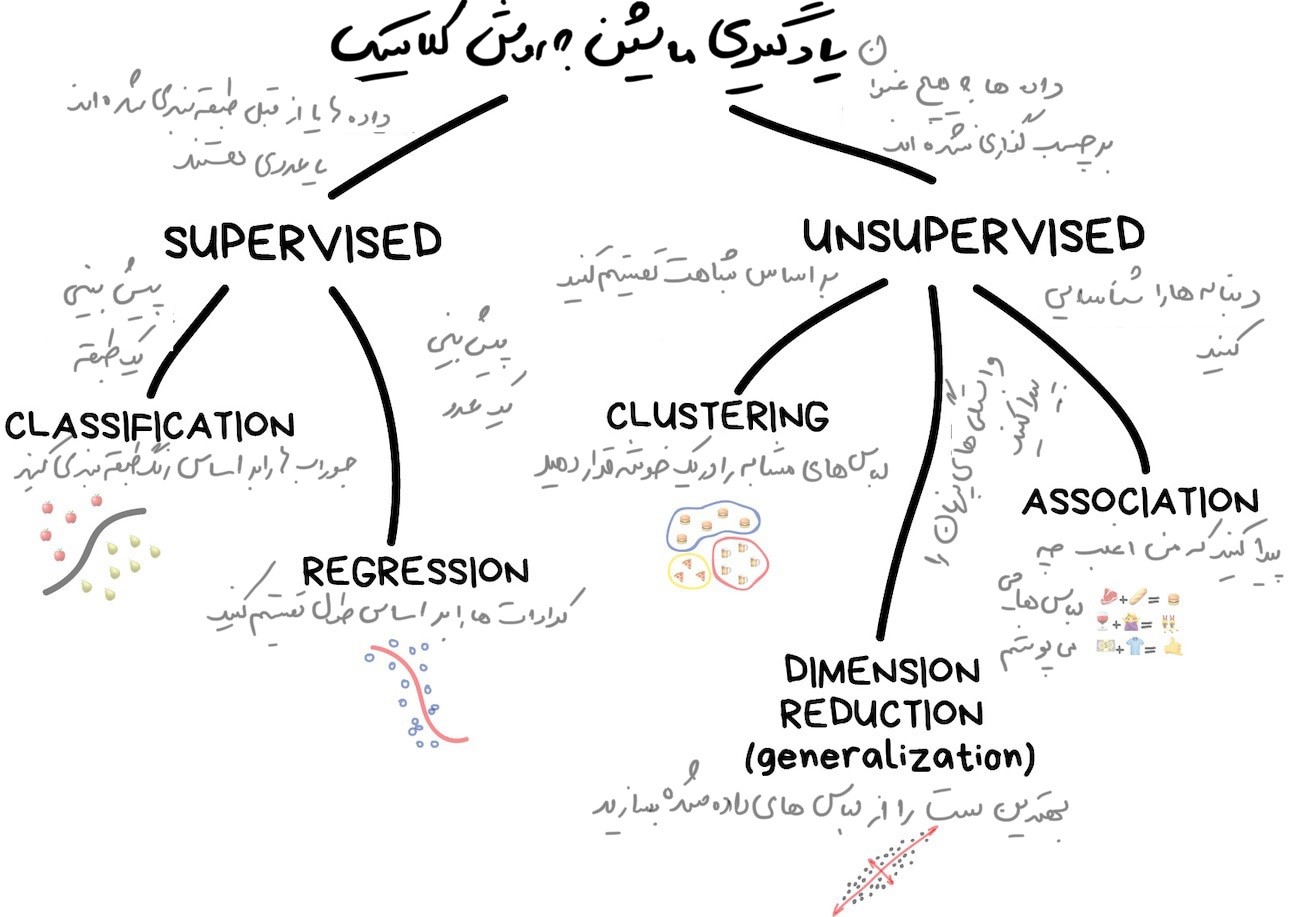
۱.۱ یادگیری تحت نظارت
یادگیری ماشین کلاسیک اغلب به دو دسته تقسیم میشود: [dt_tooltip title=”تحت نظارت”]Supervised Learning[/dt_tooltip] و [dt_tooltip title=”بدون نظارت”]Unsupervised Learning[/dt_tooltip].
در حالت اول یا همان یادگیری تحت نظارت، دستگاه یک «سرپرست» یا «معلم» دارد که تمام پاسخها را به دستگاه میدهد؛ مثلاً به ما میگوید که در تصویر دادهشده گربه وجود دارد یا سگ. معلم قبلاً دادهها را به گربهها و سگها تقسیم کرده است (با برچسبگذاری برای هر عکس مشخص کرده است که آن عکس مربوط به سگ است یا گربه) سپس دستگاه از این مثالها برای یادگیری استفاده میکند. یکبهیک آنها را تحلیل میکند و سگ و گربه را مجزا بررسی میکند.
یادگیری بدون نظارت اما به این معنی است که انبوهی از عکسهای حیوانات به دستگاه داده میشود و دستگاه بهتنهایی باید بتواند عکسهای مختلف را تشخیص دهد. دادهها برچسبگذاری نشدهاند، معلمی وجود ندارد، و ماشین سعی میکند هر الگو را بهتنهایی تشخیص دهد؛ در ادامهی این بخش در مورد این روشها صحبت خواهیم کرد.
واضح است که ماشین با معلم سریعتر یاد میگیرد؛ بنابراین در کارهای دنیای واقعی، این روش بیشتر مورد استفاده قرار میگیرد. دو نوع یادگیری تحت نظارت وجود دارد:
۱-[dt_tooltip title=”طبقهبندی”]Classification[/dt_tooltip]: یعنی پیشبینیِ دستهبندیِ یک شیء.
۲-رگرسیون: پیشبینی یک نقطه خاص در یک محورِ عددی.
طبقهبندی
“طبقهبندی اشیاء(نمونهها و دادههای دریافتی) را براساس یکی از ویژگیهای از قبل مشخصشده تقسیم میکند. بهعنوان مثال،جورابها را بر اساس رنگ، اسناد را بر اساس زبان، و موسیقیها را بر اساس ژانر تقسیم میکند.”
امروزه از این روش برای موارد زیر استفاده میشود:
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]
- فیلتر اسپم
- تشخیص زبان
- جستجوی اسناد مشابه
- تحلیل احساسات
- تشخیص کاراکترها و اعداد دستنویس
- تشخیص تقلب
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5457″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
الگوریتمهای محبوب این بخش عبارتند از: بیز ساده(Naive Bayes)، درخت تصمیم(Decision Tree)، رگرسیون پشتیبانی(Logistic Regression)، K-نزدیکترین همسایه(K-Nearest Neighbors)، ماشینِ بُردار پشتیبانی(Support Vector Machine).
| از اینجا به بعد می توانید با نظرات خود این بخش ها را تکمیل کنید. با خیال راحت مثالهایی از حوزه کاری خود را بنویسید. هر مثالی که اینجا آورده شده است بر اساس تجربۀ ذهنی خودم بوده است. |
یادگیری ماشین عمدتاً در مورد طبقهبندی چیزها(اشیاء) است. ماشین در اینجا مانند بچهای است که مرتب کردن اسباببازیهای خود را یاد میگیرد: اینجا یک ربات است، این یک ماشین، اینجا یک ماشین روبو… اوه! صبر کنید. خطا! خطا!
در طبقهبندی، شما همیشه به یک معلم نیاز دارید. دادهها باید با ویژگیها برچسبگذاری شوند تا ماشین بتواند کلاسها را بر اساس آنها مشخص کند. همهچیز را میتوان طبقهبندی کرد: کاربران را بر اساس علایق ([dt_tooltip title=”همانطور که فیدهای الگوریتمی”]Algorithmic Feeds[/dt_tooltip] انجام میدهند)، مقالات را بر اساس زبان و موضوع (که برای موتورهای جستجو مهم است)، موسیقی را بر اساس ژانر (لیستهای پخش Spotify) و حتی ایمیلهای شما را نیز میتوان طبقهبندی کرد.
در ابتدا برای فیلترکردن هرزنامهها از الگوریتم بیز ساده بهطور گسترده استفاده میشد. بهعنوان مثال دستگاه تعداد نامهای «بچهگربه» را در هرزنامه و نامههای معمولی میشمرد، سپس هر دو احتمال را با استفاده از معادلۀ بیز ضرب کرده و نتایج را جمع میکرد. و بله! این یعنی یادگیری ماشین!
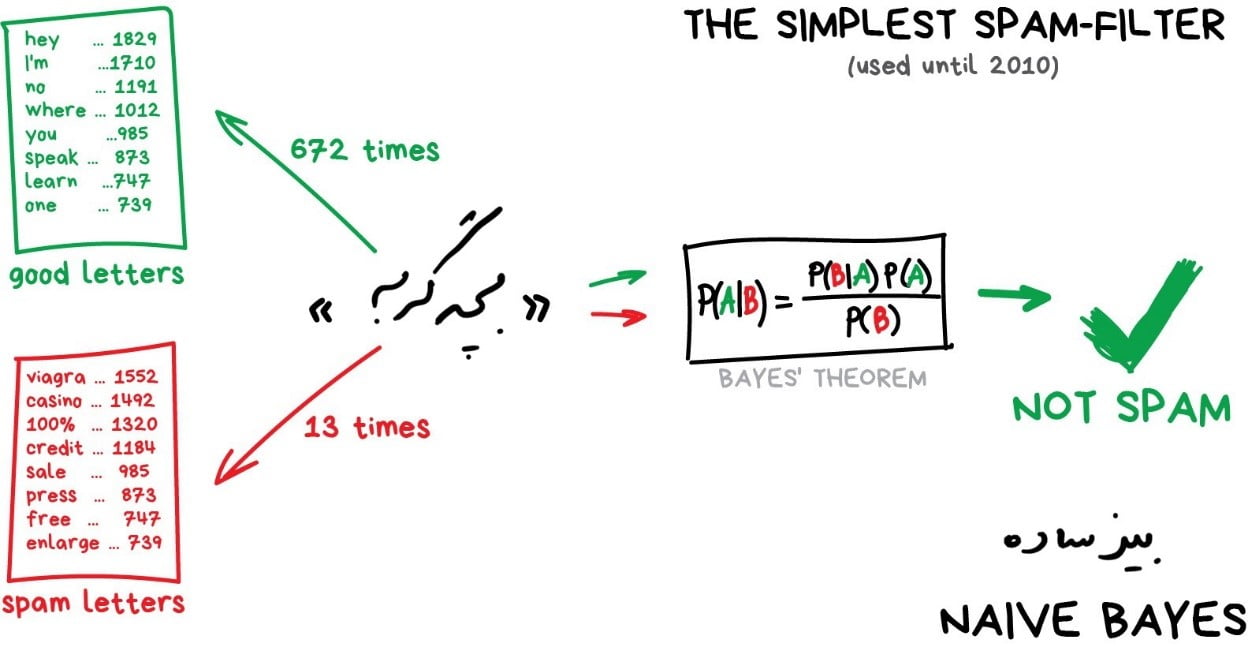 مدتی بعد، ارسالکنندگان هرزنامه، نحوۀ برخورد با فیلترهای بیزی را یاد گرفتند. یعنی با اضافه کردن بعضی کلمات «خوب» به متن، احتمال شناسایی آنها را به عنوان اسپم کم میکردند. از قضا، این روش مسمومیت بیزی[۱] نامیده شد. بیز ساده به عنوان ظریفترین و اولین مورد کاربرد در یادگیری ماشین در تاریخ ثبت شد. اما امروزه الگوریتمهای دیگری برای فیلترکردن هرزنامهها استفاده میشود.
مدتی بعد، ارسالکنندگان هرزنامه، نحوۀ برخورد با فیلترهای بیزی را یاد گرفتند. یعنی با اضافه کردن بعضی کلمات «خوب» به متن، احتمال شناسایی آنها را به عنوان اسپم کم میکردند. از قضا، این روش مسمومیت بیزی[۱] نامیده شد. بیز ساده به عنوان ظریفترین و اولین مورد کاربرد در یادگیری ماشین در تاریخ ثبت شد. اما امروزه الگوریتمهای دیگری برای فیلترکردن هرزنامهها استفاده میشود.
در اینجا یک مثال عملی دیگر از طبقهبندی میآوریم: فرض کنید به یک وام نیاز دارید. بانک چگونه متوجه میشود که آیا آن را پس میدهید یا خیر؟ راهی برای دانستن قطعی وجود ندارد. اما بانک پروفایلهای زیادی از افرادی دارد که قبلا وام گرفتهاند. آنها اطلاعاتی در مورد سن، تحصیلات، شغل، درآمد و مهمتر از همه وضعیت و نحوۀ بازپرداخت وامها یا عدم بازپرداخت آنها را دارند.
با استفاده از این دادهها میتوانیم به ماشین آموزش دهیم که الگوها را پیدا کند و پاسخ لازم را برای فرد مورد نظر دریافت کند. هیچ مشکلی برای پاسخگویی وجود ندارد. اما مسئله این است که بانک نمیتواند کورکورانه به پاسخ دستگاه اعتماد کند. اگر نقص سیستم، حملۀ هکرها یا یک راه حل سریع و میانبر توسط یک فرد وجود داشته باشد، چه میشود!؟.
برای مقابله با این مشکل، روش درخت تصمیم را داریم. در این روش تمام دادهها بهطور خودکار به مجموعهای از سؤالات بله/خیر تقسیم میشوند. بهعنوان مثال، اینکه آیا طلبکار بیش از ۱۲۸.۱۲ دلار درآمد دارد؟ ممکن است ابتدا کمی عجیب به نظر برسدولی با این حال، دستگاه با چنین سؤالاتی روبرو میشود تا دادهها را در هر مرحله به بهترین شکل تقسیم کند.
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]
با استفاده از این سوالات، درخت تصمیم درست میشود. هر چه شاخه بالاتر باشد، سؤال گستردهتر است. هر تحلیلگر معمولی میتواند این درختها را گرفته و توضیح دهد. شاید نفهمد ولی میتواند راحت توضیح دهد!
درختان تصمیم بهطور گسترده در حوزههایی که سطح بالائی از مسئولیت را دارند، استفاده میشوند. حوزههایی مانند: عیبیابی، پزشکی و امور مالی.
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5461″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
| CART و C4.5دو الگوریتم محبوب برای تشکیل درخت هستند. |
امروزه روش درخت تصمیم بهتنهایی کمتر مورد استفاده قرار میگیرد. با این حال، این الگوریتمها اغلب زیرساختهای سیستمهای بزرگ را تشکیل میدهند و مجموعۀ آنها حتی بهتر از شبکههای عصبی کار میکنند. بعداً در مورد این روش بیشتر صحبت خواهیم کرد.
| وقتی چیزی را در گوگل جستجو میکنید، دقیقاً از درختان تصمیمی استفاده میشود که طیف وسیعی از پاسخها را برای شما فراهم میکنند. موتورهای جستجو الگوریتم درخت تصمیم را دوست دارند. چون این الگوریتمها سرعت بالایی دارند. |
ماشینهای [dt_tooltip title=”بردار پشتیبان”]Support Vector Machines[/dt_tooltip] (SVM) بهدرستی محبوبترین روش طبقهبندی کلاسیک است. از این روش برای طبقهبندی همه چیز استفاده میشود: گیاهان بر اساس ظاهر در عکسها، اسناد بر اساس دستهها و غیره.
ایدۀ پشت SVM ساده است: سعی میکند دو خط بین نقاط داده شما با بیشترین حاشیه بین آنها ترسیم کند. به تصویر نگاه کنید:
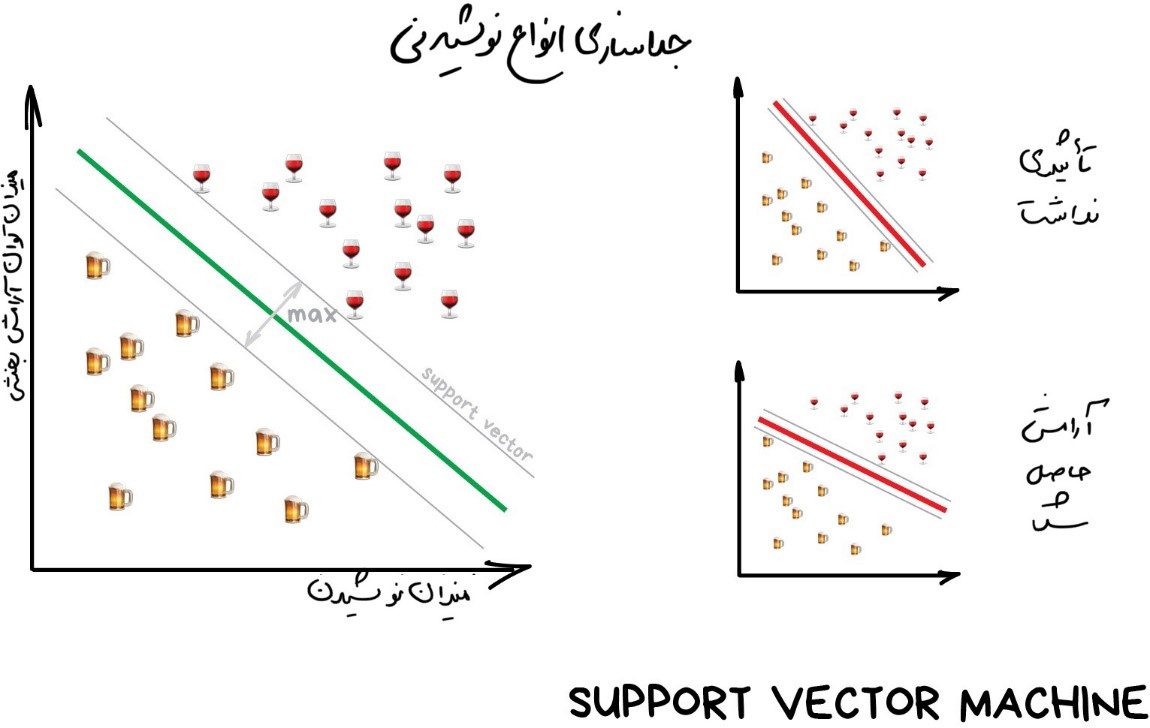
در طبقهبندی یک جنبۀ بسیار مفید وجود دارد و آن «تشخیص نابهنجاری» است. وقتی که یک ویژگی با هیچیک از طبقات مطابقت ندارد، آن را بهعنوان یک نابهنجاری مشخص میکنیم. در دنیای امروز، در پزشکی از این جنبۀ طبقهبندی استفادههای زیادی میشود، بهعنوان مثال در MRI، رایانهها تمام نواحی مشکوک یا انحرافات آزمایش را مشخص میکنند. بازارهای سهام از آن برای تشخیص رفتار غیرعادی معاملهگران و یافتن افراد نفوذی استفاده میکنند. وقتی چیزهای درست را به رایانه آموزش میدهیم، تلویحاً و بهطور خودکار، اینکه «چه چیزهایی اشتباه هستند» را نیز به آن یاد میدهیم.
امروزه معمولاً از شبکههای عصبی برای طبقهبندی استفاده میشود و این طبیعی است. چرا که این شبکهها از اول هم برای همین کار درست شدهاند!
قاعدۀ کلی این است که هرچه دادهها پیچیدهتر باشند، الگوریتم نیز پیچیدهتر است. برای متن، اعداد و جداول، من رویکردِ کلاسیک را انتخاب میکنم. مدلها در آنجا کوچکتر هستند، سریعتر یاد میگیرند و واضحتر کار میکنند ولی برای عکسها، ویدیوها و سایر چیزهای پیچیده و دادههای بزرگ، قطعاً از شبکههای عصبی استفاده میکنم.
تا پنج سال پیش میتوانستید فقط یک طبقهبندیکنندۀ چهره پیدا کنید که آن هم بر اساس SVM کار میکرد. اما امروزه با امکان انتخاب از بین صدها شبکۀ از پیش آموزشدیده، این کار بسیار آسانتر شده است. با این حال، برای فیلترهای هرزنامه چیزی تغییر
نکرده است و الگوریتمهای آن هنوز هم با SVM نوشته میشوندچرا که تا به این لحظه، دلیل خوبی برای تغییر آن وجود ندارد. حتی وبسایت شخصی من نیز دارای تشخیص هرزنامه مبتنی بر SVM در نظرات است.
رگرسیون
“از میان این نقاط یک خط بکشید! خب! این همان یادگیری ماشین است”
امروزه از این روش برای کاربردهای زیر استفاده میشود:
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]
- پیشبینی قیمت سهام
- تجزیه و تحلیل حجم تقاضا و فروش
- تشخیص پزشکی
- هر گونه همبستگی عدد-زمان
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5465″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
الگوریتمهای شناختهشدهتر این روش، [dt_tooltip title=”رگرسیون خطی”] Linear Regression[/dt_tooltip] و[dt_tooltip title=” رگرسیون چندجملهای“]Polynomial Regression[/dt_tooltip] هستند.
رگرسیون اساساً نوعی طبقهبندی است که در آن ما به جای دستهبندی، یک عدد را پیشبینی میکنیم. به عنوان مثال میتوان به قیمت خودرو بر اساس مسافت پیموده شده، ترافیک بر اساس زمان در روز، حجم تقاضا بر اساس رشد شرکت و غیره اشاره کرد. وقتی که چیزی به زمان بستگی دارد، رگرسیون عالی است.
همۀ کسانی که با امور مالی و تجزیه و تحلیل آماری کار میکنند، رگرسیون را دوست دارند. حتی در نرمافزار اکسل نیز این امکان تعبیه شده است و مفهوم آن فوقالعاده ساده و روان است. ماشین بهسادگی سعی میکند خطی بکشد که نشاندهندۀ [dt_tooltip title=”همبستگی”]Correlation[/dt_tooltip] متوسط باشد. برخلاف وقتی که ما با قلم و کاغذ این کار را انجام میدهیم، ماشین این کار را با دقت بالای ریاضی انجام داده و میانگین فاصله هر نقطه را دقیق محاسبه میکند.
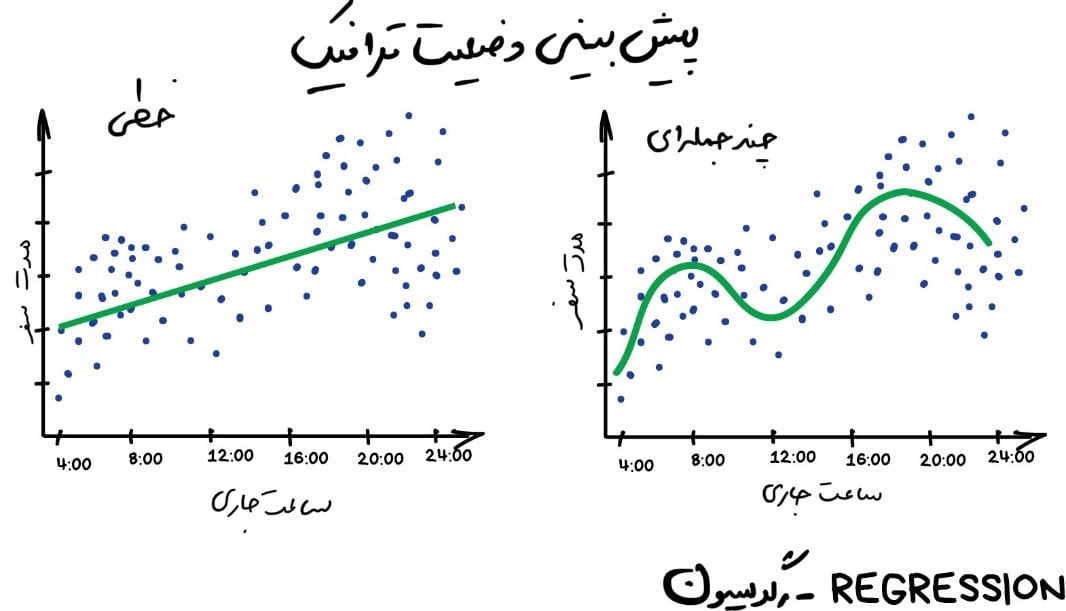
وقتی خطی که کشیده میشود مستقیم باشد، یک رگرسیون خطی داریم و وقتی منحنی است یک رگرسیون چندجملهای. اینها دو نوع اصلی رگرسیون هستند. بقیه انواع رگرسیون عجیبترند. [dt_tooltip title=”رگرسیون لجستیک”]Logistic Regression[/dt_tooltip] مانند یک گوسفند سیاه در گله استکه بهسادگی ممکن است باعث فریب شما شود، زیرا این یک روش طبقهبندی است، نه رگرسیون.
با این حال، اشکالی ندارد که با رگرسیون و طبقهبندی در کنار یکدیگر مواجه شوید. بسیاری از طبقهبندیکنندهها پس از کمی تنظیم به رگرسیون تبدیل میشوند. ما نه تنها میتوانیم طبقهبندی و دستهبندی را تعریف کنیم، بلکه میتوانیم میزان نزدیکی آنها را نیز به خاطر بسپاریم و در این حالت است که یک رگرسیون رخ میدهد.
| اگر میخواهید عمیقتر به این موضوع بپردازید، این مجموعهها را بررسی کنید: یادگیری ماشین برای انسانها. من واقعا آن را دوست دارم و توصیه می کنم! |
۱.۲ یادگیری بدون نظارت
یادگیری بدون نظارت کمی بعد، در دهه ۹۰ اختراع شد. کمتر مورد استفاده قرار میگیرد، اما گاهی اوقات ما چارۀدیگری بهجز استفاده از آن نداریم.
دادههای برچسبدار در زمره دادههای لوکس محسوب میشوند. بهعنوان مثال اگر بخوهیم یک طبقهبندی کنندۀ اتوبوس ایجاد کنیم، باید چه کنیم؟ آیا باید به صورت دستی از میلیونها اتوبوس در خیابانها عکس بگیریم و به هر کدام از آنها یک برچسب بزنیم؟ به هیچ وجه! این کار یک عمر طول میکشد، و ما خیلی کارهای مهمتری برای انجام داریم!
در این مورد کمی امید به نظام سرمایهداری وجود دارد. به لطف طبقهبندی اجتماعی، ما میلیونها کارگر و خدمات ارزان قیمت مانند کارگرهای مهاجر داریم که با ۰.۰۵ دلار آمادۀ انجام کارهای شما هستند. این قبیل کارها، معمولاً بهاینصورت انجام میشوند.
راه دیگر این است که سعی کنید از یادگیری بدون نظارت استفاده کنید. اما هیچ کاربرد عملی خوبی برای آن به یاد نمیآورم. معمولاً برای تجزیه و تحلیل دادههای اکتشافی مفید است اما نه به عنوان الگوریتم اصلی. یک فرد آموزش دیده با مدرک آکسفورد، ماشین را با انبوه دادههای بیارزش تغذیه میکند و آن را تماشا میکند. آیا خوشههایی وجود دارد؟ هیچ رابطه قابل مشاهدهای دارید؟ نه. خب! مگر نمیخواستید در علم داده کار کنید، پس کار را ادامه دهید، درست است؟
[dt_tooltip title=”خوشهبندی”] Clustering[/dt_tooltip]
“اشیاء را بر اساس ویژگیهای ناشناخته تقسیم میکند. ماشین بهترین راه را انتخاب میکند”
امروزه از این روش در موارد زیر استفاده میشود:
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]
- تقسیمبندی بازار (انواع مشتریان، وفاداری)
- ادغام نقاط نزدیک روی نقشه
- فشردهسازی تصویر
- تجزیه و تحلیل و برچسبگذاری دادههای جدید
- تشخیص رفتارهای غیرعادی
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5469″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
الگوریتمهای محبوب این روش عبارتند از: K-means-clustering، Mean-Shift، DBSCAN
خوشهبندی یک طبقهبندی بدون طبقات از پیش تعریفشده است. خوشهبندی مثل تقسیم جوراب بر اساس رنگ آنهاست وقتی که همۀ رنگهایی که وجود دارد را نمیدانیم. الگوریتم خوشهبندی در تلاش برای یافتن اشیاء مشابه (بر اساس برخی از ویژگیها) و ادغام آنها در یک خوشه است. اشیایی که دارای بسیاری از ویژگیهای مشابه هستند در یک کلاس و یا خوشه در کنار یکدیگر قرار میگیرند. در برخی از الگوریتمها، حتی میتوانید تعداد دقیق خوشههایی را که میخواهید مشخص کنید.
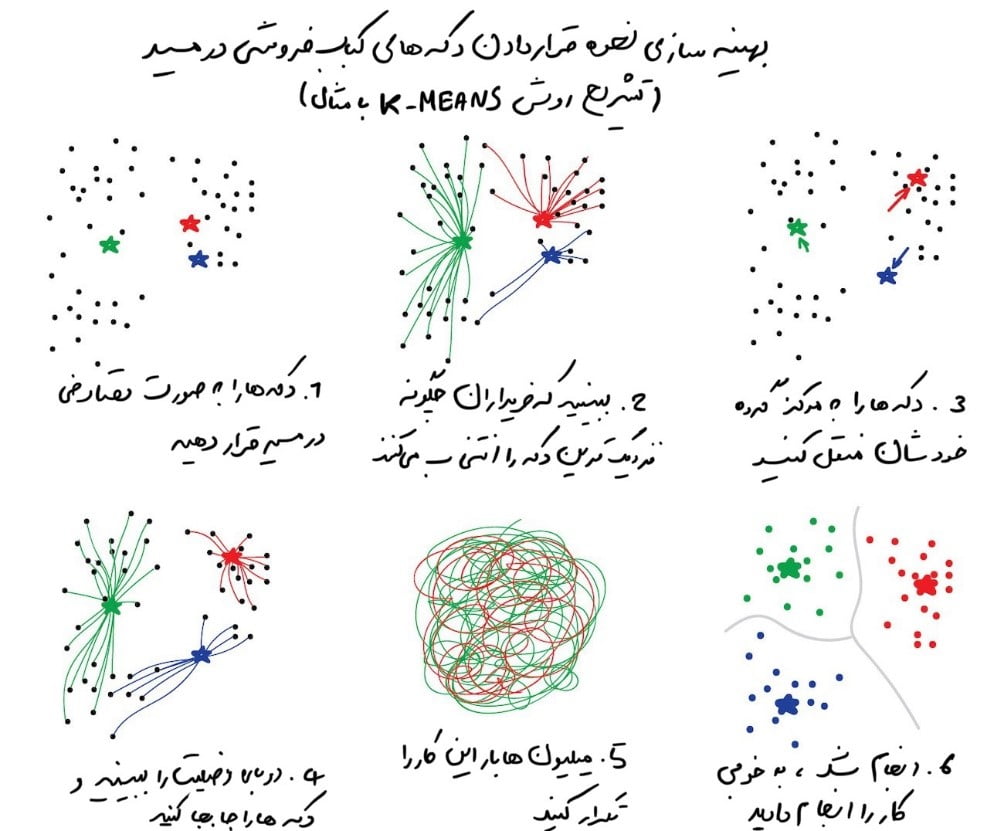 یک مثال عالی از خوشهبندی، نشانگرها در نقشه های وب هستند. وقتی به دنبال همۀ رستورانهای گیاهخواری در اطراف خود هستید، موتور خوشهبندی آنها را به صورت حبابهایی با یک عدد دستهبندی میکند. در غیر این صورت، مرورگر شما منجمد میشود و مثلاً هر سه میلیون رستوران گیاهخواری را در آن مرکز شهر شیک قرار دارند را برای شما بر روی نقشه نمایش میدهد.
یک مثال عالی از خوشهبندی، نشانگرها در نقشه های وب هستند. وقتی به دنبال همۀ رستورانهای گیاهخواری در اطراف خود هستید، موتور خوشهبندی آنها را به صورت حبابهایی با یک عدد دستهبندی میکند. در غیر این صورت، مرورگر شما منجمد میشود و مثلاً هر سه میلیون رستوران گیاهخواری را در آن مرکز شهر شیک قرار دارند را برای شما بر روی نقشه نمایش میدهد.
Apple Photos و Google Photos از خوشهبندی پیچیدهتری استفاده میکنند. آنها به دنبال چهرهها در عکسهای شما میگردند تا آلبومهایی از دوستان شما درست کنند. این برنامه نمیداند شما چندتا دوست دارید و شکل دوستان شما چگونه به نظر میرسند، اما سعی میکند ویژگیهای رایج صورت را پیدا کند. این کار نوعی خوشهبندی متداول است.
یکی دیگر از مسائل رایج در خوشهبندی فشردهسازی تصویر است. هنگام ذخیره تصویر در فایلهای PNG میتوانید پالت را مثلاً روی ۳۲ رنگ تنظیم کنید. یعنی خوشهبندی، تمام پیکسلهای «قرمز» را پیدا میکند، «قرمز متوسط» را محاسبه میکند و آن را برای همه پیکسلهای قرمز تنظیم میکند(یعنی به جای همه پیکسلهای قرمز عدد قرمز متوسط را در نظر میگیرد). وقتی تعداد رنگها کمتر شود، اندازه فایل نیز کمتر میشود و این یعنی سود(فشردگی بیشتر)!
با این حال، ممکن است با رنگ هایی مانند رنگ های فیروزهای مشکل داشته باشید. مشخص نیست این رنگ سبز است و یا آبی؟ در اینجاست که الگوریتم K-Means پا به میدان میگذارد.
در این روش، ۳۲ نقطه رنگی را به طور تصادفی در پالت مشخص میکند. اکنون، آنها را به عنوان مرکز در نظر میگیرد. نقاط باقیمانده، با توجه به فاصله آنها با هر مرکز، به نزدیکترین مرکز علامتگذاری میشوند. بنابراین، ما نوعی کهکشان در اطراف این ۳۲ رنگ به دست میآوریم. سپس هر یک از این نقاط مرکزی را به مرکز کهکشانش میبریم و این کار را تا زمانی که مرکزها از حرکت بایستند، تکرار میکنیم. خب! کار انجام شد.
خوشهها تعریفشده و پایدار هستند و دقیقاً ۳۲ مورد از آنها وجود دارد. در اینجا یک توضیح بیشتر در دنیای واقعی وجود دارد:پیداکردن مرکزها راحت است. اگرچه در زندگی واقعی، خوشهها همیشه دایرهشکل نیستند؛ بیایید تصور کنیم که شما یک زمینشناس هستید. و باید چند کانی مشابه را روی نقشه پیدا کنید. در اینصورت، خوشهها میتوانند بهشکل عجیبی شکل گرفته و حتی تودرتو باشند. همچنین، شما حتی نمیدانید چه تعداد از آنها را باید انتظار داشت ۱۰تا؟ ۱۰۰تا؟
K-means در اینجا مناسب نیست، اما DBSCAN میتواند مفید باشد؛ فرض کنید، نقاط ما مردمی هستند که در میدان شهر جمع شدهاند. هر سه نفر را پیدا کنید که نزدیک به هم ایستادهاند و از آنها بخواهید که دست همدیگر را بگیرند. سپس، به آنها بگویید که شروع به گرفتن دست اطرافیانی کنند که میتوانند به آنها دسترسی پیدا کنند. و …، و همینطور تا زمانی که هیچکس نتواند دست کسی را بگیرد. این اولین خوشۀ ماست. این فرآیند را تا زمانی که همه گروهبندی شوند تکرار کنید. کار انجام شد!
| یک امتیاز خوب: شخصی که دست کسی را نگرفته است، یک ناهنجاری است. |
اگر این کار را در حرکت ببینید، جالب به نظر می رسد:

| به خوشه بندی علاقه دارید؟ این مطلب را بررسی کنید: ۵ الگوریتم خوشه بندی که دانشمندان داده باید بدانند. |
درست مانند طبقهبندی، خوشهبندی میتواند برای تشخیص نابهنجاریها استفاده شود. بهعنوان مثال، آیا کاربر پس از ثبتنام و ورود به سیستم، غیرعادی رفتار میکند؟ اجازه دهید دستگاه ورود او را بهطور موقت ممنوع کند و [dt_tooltip title=”یک بلیط “]Ticket[/dt_tooltip] برای پشتیبانی ایجاد کند تا آن را بررسی کند. شاید ربات باشد. ما حتی نیازی نداریم بدانیم “رفتار عادی” چیست، فقط تمام اقدامات کاربر را در مدل خود آپلود میکنیم و به ماشین اجازه میدهیم تصمیم بگیرد که آیا یک کاربر “معمولی” است یا نه.
این روش در مقایسه با روش طبقهبندی آنقدرها درست کار نمیکند، اما امتحانکردن آن هرگز ضرری ندارد.
[dt_tooltip title=”کاهش ابعادی”]Dimensionality Reduction[/dt_tooltip] ([dt_tooltip title=”تعمیم”]Generalization[/dt_tooltip])
«ویژگیهای خاص را در سطوح بالاتر گرد هم میآورد و تجمیع و متمرکز میکند»
امروزه از این روش برای موارد زیر استفاده می شود:
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]
- [dt_tooltip title=”سیستمهای توصیه کننده”]Recommender systems[/dt_tooltip] (★)
- تجسمهای زیبا
- مدلسازی موضوع و جستجوی اسناد مشابه
- تجزیه و تحلیل تصویر جعلی
- مدیریت ریسک
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5475″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
الگوریتمهای محبوب این روش عبارتند از:[dt_tooltip title=”تجزیه و تحلیل مؤلفه اصلی (PCA)”]Principal Component Analysis[/dt_tooltip]،[dt_tooltip title=” تجزیه ارزش واحد (SVD)”]Singular Value Decomposition[/dt_tooltip]،[dt_tooltip title=”تخصیص دیریکله پنهان (LDA)”] Latent Dirichlet Allocation[/dt_tooltip]،[dt_tooltip title=”تجزیه و تحلیل معنایی نهفته”] Latent Semantic Analysis [/dt_tooltip](LSA، pLSA، GLSA)، t-SNE (برای تجسم)
قبلاً این روشها توسط دانشمندان دادهی فعال و سختکوش مورد استفاده قرار میگرفت که مجبور بودند “چیزی جالب” را در انبوهی از اعداد بیابند. زمانی که نمودارهای اکسل دیگر کمکی نکردند، ماشینها را مجبور به الگویابی کردند. بهاین ترتیب آنها بهسراغ روشهای کاهش ابعادی یا [dt_tooltip title=”یادگیری ویژگی”]Feature Learning[/dt_tooltip] رفتند.
استفاده از انتزاعیات برای افراد همیشه راحتتر از مجموعهای از ویژگیهای پراکنده است. به عنوان مثال، ما میتوانیم همه سگها را با گوشهای مثلثی، بینیهای بلند و دمهای بزرگ با هم ادغام کنیم تا یک انتزاع خوب مثل “سگ چوپان” بسازیم. بله! ما برخی اطلاعات در مورد سگهای چوپان خاص را از دست میدهیم، اما این انتزاع جدید برای نامگذاری و توضیح اهداف بسیار مفیدتر است. بهعنوان یک امتیاز، مدلهای «انتزاعی» سریعتر یاد میگیرند، کمتر [dt_tooltip title=”بیشبرازش”]فرض کنید برای امتحانِ آخرِ ترم درس میخوانید. استاد به شما ۱۰۰ عدد نمونه سوال داده است تا بتوانید خود را برای امتحان آماده کنید. اگر شما طوری مطالعه کنید که فقط این ۱۰۰ نمونه سوال را کامل بلد باشید و هر سوالِ دیگری که کمی با این ۱۰۰ سوال فاصله داشته باشد، اشتباه جواب دهید، یعنی ذهنِ شما بر روی این سوالاتِ Overfit یا بیشبرازش شده است. [/dt_tooltip] میکنند و از تعداد ویژگیهای کمتری استفاده میکنند.
| Projecting 2D-data to a line (PCA) |
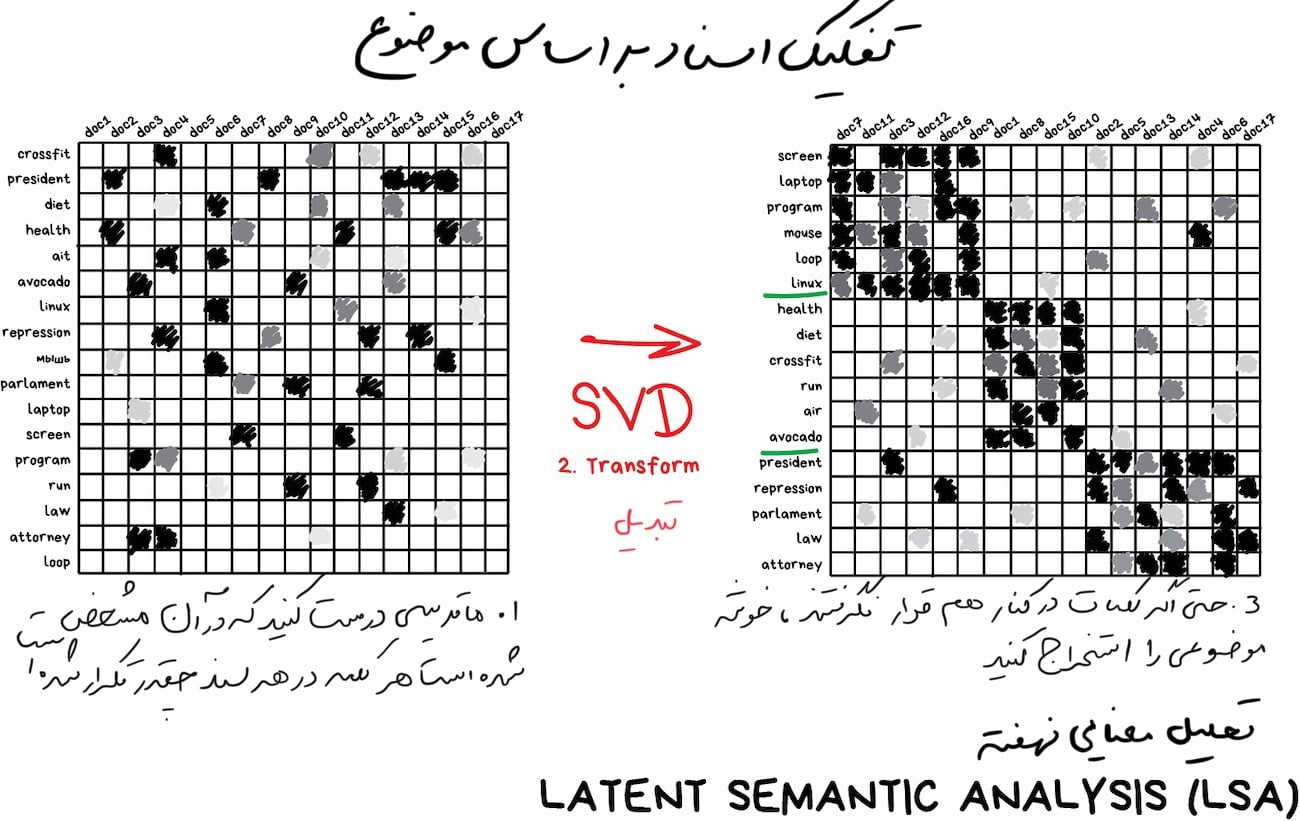
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]این الگوریتمها به ابزاری شگفتانگیز برای مدلسازی موضوع تبدیل شدهاند. ما میتوانیم از کلمات خاص به معانی آنها انتزاع کنیم. این کاری است که تحلیل معنایی نهفته (LSA) انجام میدهد. این روش وقتی براساس تعداد دفعات مشاهدۀ کلمه در موضوع کار میکند، دقیق است. بهعنوان مثال مطمئناً اصطلاحات فنی بیشتری در مقالات فناوری وجود دارد و یا اسامی سیاستمداران بیشتر در اخبار سیاسی و … یافت میشود.
بله! ما فقط میتوانیم از همۀ کلمات موجود در مقالات خوشههایی بسازیم، اما همۀ اتصالات مهم بین آنها را از دست میدهیم (مثلاً معنای یکسان باتری و آکومولاتور در اسناد مختلف). LSA آن را به درستی مدیریت میکند، بههمین دلیل است که آن را “معنای نهفته” مینامند.
بنابراین، ما باید کلمات و اسناد را به یک ویژگی متصل کنیم تا این ارتباطات نهفته را حفظ کنیم و به نظر میرسد که تجزیه ارزش واحد (SVD) این مشکل را برطرف کرده و خوشههای موضوعی مفیدی را از کلمات دیدهشده با هم پیدا میکند.
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5479″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
فرض کنید برای امتحانِ آخرِ ترم درس میخوانید. استاد به شما ۱۰۰ عدد نمونه سوال داده است تا بتوانید خود را برای امتحان آماده کنید. اگر شما طوری مطالعه کنید که فقط این ۱۰۰ نمونه سوال را کامل بلد باشید و هر سوالِ دیگری که کمی با این ۱۰۰ سوال فاصله داشته باشد، اشتباه جواب دهید، یعنی ذهنِ شما بر روی این سوالاتِ Overfit یا بیشبرازش شده است.
 [dt_tooltip title=”سیستمهای توصیهکننده و فیلتر مشارکتی”]Collaborative Filtering[/dt_tooltip] یکی دیگر از کاربردهای فوقالعاده محبوب روش کاهش ابعادی است. به نظر میرسد که اگر از آن برای رتبهبندی انتزاعی کاربران استفاده کنید، یک سیستم عالی برای توصیه فیلم، موسیقی، بازی و هر آنچه که در این زمینه میخواهید، بهدست خواهید آورد.
[dt_tooltip title=”سیستمهای توصیهکننده و فیلتر مشارکتی”]Collaborative Filtering[/dt_tooltip] یکی دیگر از کاربردهای فوقالعاده محبوب روش کاهش ابعادی است. به نظر میرسد که اگر از آن برای رتبهبندی انتزاعی کاربران استفاده کنید، یک سیستم عالی برای توصیه فیلم، موسیقی، بازی و هر آنچه که در این زمینه میخواهید، بهدست خواهید آورد.
| در اینجا میخواهم کتاب مورد علاقه خود “[dt_tooltip title=”برنامهریزی هوش جمعی”]Programming Collective Intelligence[/dt_tooltip]” را توصیه کنم. کتاب در دوران تحصیل در دانشگاه همیشه کنار من بود! |
درک کامل این انتزاع ماشین به سختی امکان پذیر است، اما می توان برخی از همبستگیها را با نگاهی دقیقتر مشاهده کرد. برخی از آنها با سن کاربر مرتبط است مثلاً بچهها Minecraft بازی میکنند و کارتونها را بیشتر تماشا میکنند. دیگران با ژانر فیلم یا سرگرمیهای کاربر مرتبط هستند.
ماشینها به این مفاهیم سطح بالا، حتی بدون درک آنها، تنها بر اساس دانش رتبهبندی کاربران، میرسند. خیلی خوب! آقای کامپیوتر! اکنون میتوانیم پایاننامهای بنویسیم که چرا چوببرهای ریشدار عاشق سریال پونی [dt_tooltip title=”کوچولوی من”]یک مجموعه تلویزیونی انمیشین است که بر اساس مجموعه اسباب بازیهای «my little pony» ساخته شدهاست. این سریال در ۱۲ اکتبر ۲۰۱۹ پایان یافت و محبوبیت بسیار زیادی کسب کرده است.[/dt_tooltip] هستند.(اشاره به آن دارد که کار خیلی معنایی شگفتانگیزی میشود با کامپیوتر انجام داد.)
[dt_tooltip title=”یادگیری قوانین انجمنی”]
Association rule learning
[/dt_tooltip]
امروزه از این روش برای موارد زیر استفاده می شود:
- پیشبینی فروش و تخفیف
- تجزیه و تحلیل کالاهایی که با هم خریداری شدهاند
- قراردادن محصولات در قفسهها
- تجزیه و تحلیل الگوهای وبگردی
الگوریتمهای محبوب این روش عبارتند از: Apriori، Euclat، FP-growth.
کاربردهای این رویکرد شامل تمام روشهای تجزیه و تحلیل سبد خرید، خودکارسازی استراتژی بازاریابی و سایر کارهای مرتبط با رویدادها میشود. وقتی دنبالهای از چیزی دارید و میخواهید الگوهایی را در آن پیدا کنید بهتر است این روش را امتحان کنید.
فرض کنید مشتری یک بسته ششتایی نوشابه را میگیرد و به صندوق میرود. آیا باید کیک کلوچهای را در راه قرار دهیم؟ هر چند وقت یکبار مردم آنها را با هم میخرند؟ بله! احتمالاً برای نوشابه و کیک کار میکند، اما چه توالی دیگری را میتوانیم پیشبینی کنیم؟ آیا یک تغییر کوچک در چینش کالاها میتواند منجر به افزایش قابل توجه فروش و بهدنبال آن سودآوری بیشتر شود؟
همین امر در مورد تجارت الکترونیک نیز صدق میکند. این کار در آنجا جالبتر است: مشتری دفعه بعد چه چیزی میخرد؟
نمیدانم که چرا به نظر میرسد یادگیری قوانین انجمنی در بحث یادگیری ماشین کمتر مورد توجه قرار گرفته است. روشهای کلاسیک، مبتنی بر نگاهی مستقیم به تمام کالاهای خریداری شده با استفاده از درختان یا مجموعهها است. الگوریتمها فقط میتوانند الگوها را جستجو کنند، اما نمیتوانند آنها را در نمونههای جدید تعمیم یا بازتولید کنند.
در دنیای واقعی، هر فروشگاه بزرگ خردهفروشی راهحل اختصاصی خود را میسازد، بنابراین اینجا، مکان مناسبی برای انقلاب کردن نیست. بالاترین سطح فناوری در اینجا، سیستمهای توصیه کننده است. اگرچه، ممکن است من از مسیر پیشرفت این حوزه آگاه نباشم.

[dt_tooltip title=”بخش دوم: یادگیری تقویتی”]Reinforcement Learning[/dt_tooltip]
“روباتی را در یک مارپیچ پر پیچوخم رها کنید و بگذارید راه خروجی را پیدا کند”
از یادگیری تقویتی امروزه برای موارد زیر استفاده میشود:
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]
- ماشینهای خودران
- جاروبرقی ربات
- بازیها
- معاملات خودکار
- مدیریت منابع سازمانی
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5483″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
الگوریتم های محبوب: Q-Learning، SARSA، DQN، A3C،[dt_tooltip title=”الگوریتم ژنتیک”]Genetic Algorithm[/dt_tooltip]
در غایت این روش، به چیزی میرسیم که شبیه هوش مصنوعی واقعی است. در بسیاری از مقالات، یادگیری تقویتی در جایی بین یادگیری تحتنظارت و بدوننظارت قرار میگیرد. ولی در ظاهر هیچ وجه اشتراکی با هم ندارند! آیا این به خاطر نام است؟
یادگیری تقویتی در مواردی استفاده میشود که مسألۀ شما بههیچوجه مربوط به دادهها نیست، اما محیطی برای کار و زندگی دارید. مانند دنیای بازیهای ویدیویی یا شهری برای ماشینهای خودران.
آگاهی از تمام قوانین جادهای در جهان، به رانندۀ خودکار نحوۀ رانندگی در جادهها را آموزش نمیدهد. صرف نظر از اینکه چقدر داده جمعآوری میکنیم، هنوز نمیتوانیم همۀ موقعیتهای ممکن را پیشبینی کنیم. بههمین دلیل است که هدف این روش به حداقل رساندن خطا است، نه پیشبینی تمام حرکات.
| یادگیری ماشین در بازیهای ویدئویی | |
| https://www.youtube.com/embed/qv6UVOQ0F44 |
زنده ماندن در یک محیط، ایدۀ اصلی یادگیری تقویتی است. ربات کوچک نحیف را در یک زندگی واقعی رها کنید، آن را برای اشتباهات مجازات کنید و برای کارهای درست به او پاداش بدهید. به همان روشی که به بچههایمان آموزش می دهیم، درست است؟
راه مؤثرتر در اینجا، ساختن یک شهر مجازی است بهطوری که به ماشین خودران اجازه دهیم ابتدا در این مکان مجازی، تمام ترفندهای خود را یاد بگیرد. در حال حاضر ما خلبانان خودکار را دقیقاً بههمین شکل آموزش میدهیم. یک شهر مجازی براساس یک نقشۀ واقعی ایجاد کنید، و آن را با عابران پیاده پر کنید و اجازه دهید ماشین یاد بگیرد که تا حد امکان کمتر مردم را بهقتل برساند. زمانی که نسبت به ماشین در این شهر مصنوعی [dt_tooltip title=”(GTA)”]اتومبیل دزدی بزرگ اولین بازی از سری بازی های اتومبیل دزدی بزرگ است که در سال ۱۹۹۷ توسط بی ام جی اینتراکتیو منتشر شده است. این بازی به بازیکن اجازه می دهد که نقش یک تبهکار را ایفا کند که آزادانه در یک شهر بزرگ پرسه می زند و ماموریت های مختلفی مانند دزدی از بانک، قتل و جرائم دیگر را انجام می دهد.[/dt_tooltip] اطمینان معقولی کسب شد، برای آزمایش در خیابانهای واقعی آزاد میشود. چقدر سرگرم کننده!
ممکن است دو رویکرد متفاوت وجود داشته باشد: رویکرد مبتنی بر مدل و رویکرد بدون مدل.
مبتنی بر مدل به این معنی است که ماشین باید یک نقشه یا قطعات آن را به خاطر بسپارد. این یک رویکرد کاملاً منسوخ است زیرا غیرممکن است که خودروهای خودران ضعیف کل سیاره و یا شرایط و حالات ممکن را به خاطر بسپارند.
در یادگیری بدون مدل، خودرو هر حرکتی را به خاطر نمیسپارد، بلکه سعی میکند موقعیتها را تعمیم دهد و در عین کسب حداکثر پاداش، منطقی عمل کند. اتومبیل دزدی بزرگ (GTA) اولین بازی از سری بازی های اتومبیل دزدی بزرگ است که در سال ۱۹۹۷ توسط بی ام جی اینتراکتیو منتشر شده است. این بازی به بازیکن اجازه می دهد که نقش یک تبهکار را ایفا کند که آزادانه در یک شهر بزرگ پرسه می زند و ماموریت های مختلفی مانند دزدی از بانک، قتل و جرائم دیگر را انجام می دهد.
اتومبیل دزدی بزرگ (GTA) اولین بازی از سری بازی های اتومبیل دزدی بزرگ است که در سال ۱۹۹۷ توسط بی ام جی اینتراکتیو منتشر شده است. این بازی به بازیکن اجازه می دهد که نقش یک تبهکار را ایفا کند که آزادانه در یک شهر بزرگ پرسه می زند و ماموریت های مختلفی مانند دزدی از بانک، قتل و جرائم دیگر را انجام می دهد.
اخبار مربوط به شکست دادن یک بازیکن برتر توسط هوش مصنوعی در بازی Go را به خاطر دارید؟ مدت کوتاهی قبل از این [dt_tooltip title=”ثابت شد”]برای اطلاع از نحوه این اثبات میتوانید به سایت زیر مراجعه نمائید:
https://motherboard.vice.com/en_us/article/vv7ejx/after-2500-years-a-chinese-gaming-mystery-is-solved[/dt_tooltip]که تعداد ترکیبات در این بازی از تعداد اتمهای جهان بیشتر است.
این بدان معنی است که دستگاه نمیتواند همه ترکیبها را به خاطر بسپارد و در نتیجه برنده Go شود (همانطور که در شطرنج نیز همین طور بود). اما در عوض در هر نوبت بازی، به سادگی بهترین حرکت را برای هر موقعیتی انتخاب میکرد و به اندازه کافی خوب عمل کرد تا از یک انسان در بازی پیشی بگیرد.
این رویکرد همان مفهوم اصلی است که در پشت الگوریتمهای Q-learning و مشتقات آن (SARSA و DQN) است. “Q” مخفف “Quality” است زیرا یک ربات یاد میگیرد که “باکیفیتترین” عمل را در هر موقعیت انجام دهد و همه موقعیتها بهعنوان یک فرآیند [dt_tooltip title=”مارکوفی”]فرایندهای تصمیمگیری مارکوف (به انگلیسی: Markov decision process) (به اختصار: MDPs) یک چارچوب ریاضی است برای مدلسازی تصمیمگیری در شرایطی که نتایج تا حدودی تصادفی و تا حدودی تحت کنترل یک تصمیمگیر است. MDPs برای مطالعه طیف گستردهای از مسائل بهینه سازی که از طریق برنامهنویسی پویا و تقویت یادگیری حل میشوند مفید است. برای مطالعه بیشتر به آین آدرس مراجعه کنید. [/dt_tooltip] ساده به خاطر سپرده میشوند.
چنین ماشینی میتواند میلیاردها موقعیت را در یک محیط مجازی آزمایش کند و بهیاد بیاورد که کدام راهحلها منجر به پاداش بیشتری شده است. اما چگونه میتواند موقعیتهای قبلاً دیدهشده را از یک موقعیت کاملاً جدید متمایز کند؟ اگر یک ماشین خودران در یک گذرگاه جاده باشد و چراغ راهنمایی سبز شود، بهاین معنی است که اکنون می تواند برود؟ اگر آمبولانسی با عجله در خیابانی در آن نزدیکی باشد چه؟

پاسخ امروز «هیچ کس نمیداند» است. جواب آسانی وجود ندارد. محققان دائماً در جستجوی آن هستند، اما در عین حال تنها راهحلهایی حدودی و موقتی برای آن پیدا میکنند. برخی همۀ موقعیتها را بهصورت دستی کدگذاری میکنند که به آنها اجازه.
میدهد موارد استثنایی را حل کنند. مانند[dt_tooltip title=”مسالۀ تراموا”]مسئلهٔ تراموا (Trolley problem یا Tramway) یک آزمایش فکری مشهور در زمینهٔ فلسفه اخلاق است. صورت کلی مسئله به این صورت است که فرض میکند تراموایی روی ریل راهآهن در حال حرکت است و پنج نفر سر راه آن هستند و تراموا مستقیماً در حال رفتن به سمت آنهاست و شما به عنوان ناظر در نزدیکی صحنه و نزدیک به یک اهرم هستید که با کشیدن آن تراموا به ریل دیگری که تنها یک نفر روی آن است هدایت میشود، شما دو انتخاب دارید: ۱) هیچ اقدامی نکنید که این مساوی با کشتهشدن آن پنج نفر روی ریل اصلی است. ۲) با کشیدن اهرم، تراموا را به سمتی هدایت کنید که موجب کشتهشدن آن یک نفر خواهد شد. انتخاب درست چیست؟[/dt_tooltip] دیگران به عمق میروند و به شبکههای عصبی اجازه میدهند که کار کشف آن را انجام دهند. این مسیر ما را به تکامل Q-learning با نام شبکۀ عمیق Q (DQN) هدایت کرد. اما این روشها گلولۀ نقرهای هم نیستند چه برسد به طلائی!
یادگیری تقویتی برای یک فرد معمولی مانند یک هوش مصنوعی واقعی به نظر می رسد. زیرا باعث میشود فکر کنید وای! این دستگاه در موقعیتهای واقعی تصمیم میگیرد!؟ این موضوع در حال حاضر خیلی پر سر و صدا و تبلیغاتی شده است و با سرعتی باورنکردنی در حال پیشرفت است و با شبکههای عصبی تلاقی میکند تا تعجب شما را بیشتر برانگیزد. دنیای شگفتانگیز فناوریها!
خارج از موضوع:
زمانی که من دانشجو بودم، الگوریتمهای ژنتیک (به لینک توجه کنید تصویر جالبی دارد) واقعاً محبوب بودند. موضوع در مورد رهاسازی یک دسته ربات در یک محیط واحد و وادار کردن آنها برای رسیدن به هدف است تا زمانی که بمیرند. سپس بهترینها را انتخاب میکنیم، آنها را به هم پیوند میزنیم، و برخی از ژنها را جهش میدهیم و شبیهسازی را دوباره اجرا میکنیم. بعد از چند میلیارد سال به یک موجود باهوش دست خواهیم یافت. شاید! تکامل در بهترین حالت!
الگوریتمهای ژنتیک به عنوان بخشی از یادگیری تقویتی در نظر گرفته میشوند و مهمترین ویژگیای که آنها دارند و با یک دهه تمرین ثابت شده است، این است که: هیچکس در مورد آنها حرفی نمیزند.
بشریت هنوز نتوانسته است به روشی با الگوریتمهای ژنتیک دست یابد که موثرتر از روشهای دیگر باشد. اما آنها برای آزمایشهای دانشجویی عالی هستند و به افراد اجازه میدهند رؤسای دانشگاه خود را در مورد “هوش مصنوعی” بدون این که کار زیادی انجام دهند، هیجانزده کنند. و البته یوتیوب نیز آن را دوست دارد.
[dt_tooltip title=”بخش سوم: روشهای چندگانۀ ترکیبی“]Ensemble Methods[/dt_tooltip]
“انبوه درختهای احمق که یاد میگیرند اشتباهات یکدیگر را تصحیح کنند”
امروزه برای موارد زیر استفاده میشود:
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]
- هرچیزی که متناسب با رویکردهای یادگیری ماشین کلاسیک باشد (اما بهتر عمل میکند)
- سیستمهای جستجو (★)
- بینایی کامپیوتر
- تشخیص اشیا
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5487″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
الگوریتمهای محبوب: Random Forest، Gradient Boosting
زمان استفاده از روشهای مدرن و بزرگ رسیده است. مجموعهها و شبکههای عصبی دو مبارز اصلی هستند که مسیر ما را بهسوی یک نتیجۀ منحصربفرد و شگفتانگیز هموار میکنند. امروزه این روشها دقیقترین نتایج را تولید میکنند و بهطور گسترده در تولید استفاده میشوند.
با این حال، شبکههای عصبی امروز همۀ تبلیغات را به خود اختصاص دادهاند، در حالی که کلماتی مانند “[dt_tooltip title=”تجمیعپردازی”]Bagging[/dt_tooltip]” یا “[dt_tooltip title=”تقویت”]Boosting[/dt_tooltip]” در سایت [dt_tooltip title=”TechCrunch”]وب گاهی است که در زمینه خبررسانی، تجزیه و تحلیل فناوریها فعالیت میکند. این وب سایت توسط مایکل ارینگتون در سال ۲۰۰۵ تأسیس شد و برای اولین بار در تاریخ ۱۱ ژوئن ۲۰۰۵ منتشر شد.رتبه اول در رده اطلاعات فناوری داراست.در ۱۰ فوریه ۲۰۱۰ دارای ۴۵۶۳۰۰۰ مشترک خوراک RSS بود.[/dt_tooltip] کمیاب هستند.
با وجود تمام اثربخشی، ایدۀ پشت این موارد بسیار ساده است. اگر مجموعهای از الگوریتمهای ناکارآمد را انتخاب کنید و آنها را مجبور کنید اشتباهات یکدیگر را تصحیح کنند، کیفیت کلی یک سیستم حتی از بهترین الگوریتمهای منفرد بالاتر خواهد بود.
حتی اگر از ناپایدارترین الگوریتمهایی استفاده کنید که با یک [dt_tooltip title=”اختلال”]Noise[/dt_tooltip] کوچک در دادههای ورودی نتایج کاملاً متفاوتی را پیشبینی میکنند، با استفاده از این رویکرد نتایج بهتری دریافت خواهید کرد؛ مانند درختان رگرسیون و تصمیم. این الگوریتمها حتی به یک عدد پرت در دادههای ورودی آنقدر حساس هستند که مدلها را دیوانه کند.
در واقع این همان چیزی است که به آن نیاز داریم.
ما میتوانیم از هر الگوریتمی که میشناسیم برای ایجاد یک روش چندگانه استفاده کنیم. فقط یکدسته الگوریتم طبقهبندیکننده را بگذارید وسط، بعد آنها را با رگرسیون تلفیق کنید و اندازهگیری دقت را هم فراموش نکنید. تجربۀ من میگوید حتی از Bayes یا KNN هم در اینجا استفاده نکنید. اگرچه “گنگ” هستند، اما آنها واقعاً پایدار هستند. کسلکننده و قابل پیشبینی!
در عوض، سه روش آزمایششده و چالشبرانگیز برای روشهای چندگانه وجود دارد.
[dt_tooltip title=”انبارهسازی“]Stacking[/dt_tooltip]
در این روش، خروجی چندین مدل موازی بهعنوان ورودی به آخرین مدل ارسال میشود و آخرین مدل است که تصمیم نهایی را میگیرد. مثل فردی که از دوستان دیگرش نظر میپرسد اما خودش تصمیم نهایی را میگیرد.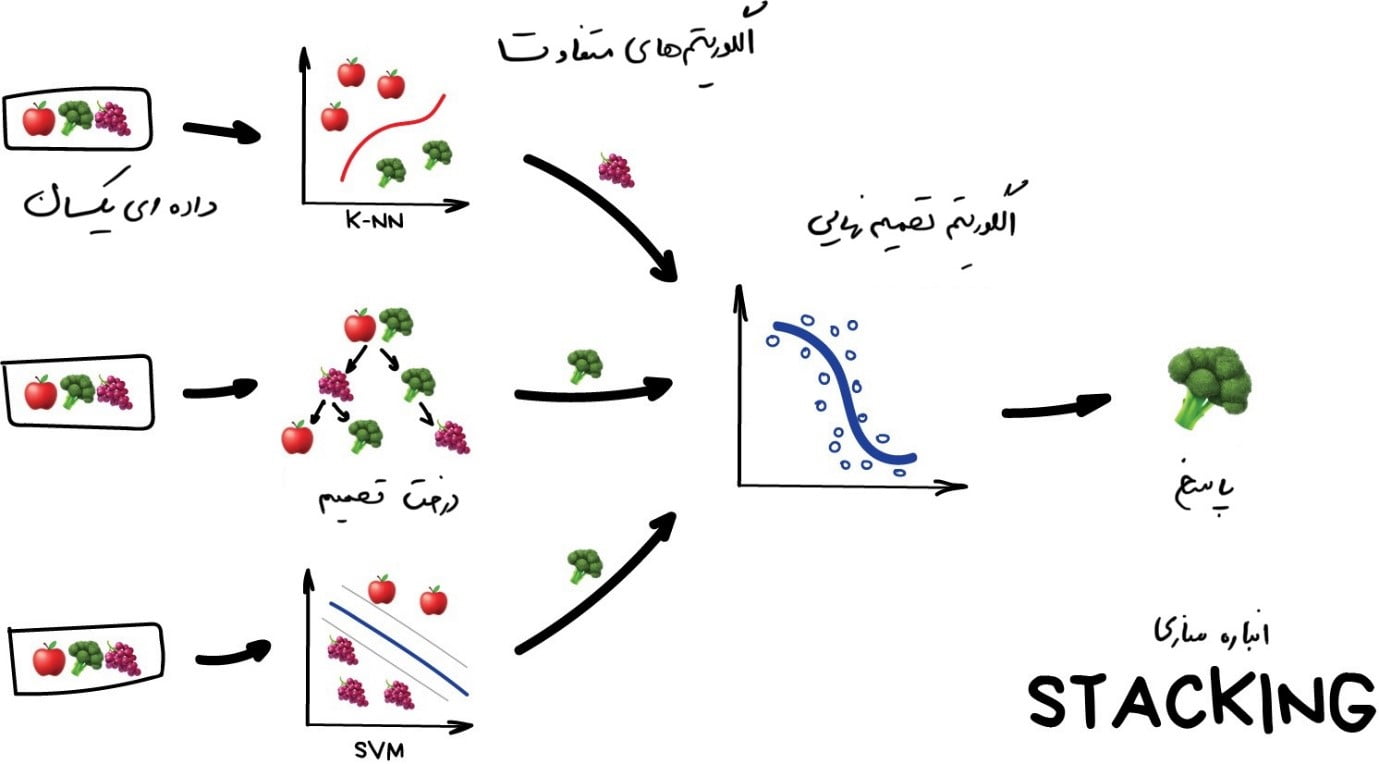
در اینجا بر کلمه “تفاوت” تأکید میشود. اِعمال الگوریتمهای مشابه روی دادههای یکسان بیمعنی است. انتخاب الگوریتمها کاملاً به شما بستگی دارد. با این حال، برای مدل تصمیمگیری نهایی، رگرسیون معمولاً انتخاب خوبی است.
براساس تجربۀ من، روش انبارهسازی در عمل کمتر محبوب است، زیرا دو روش دیگر دقت بهتری را ارائه میدهند.
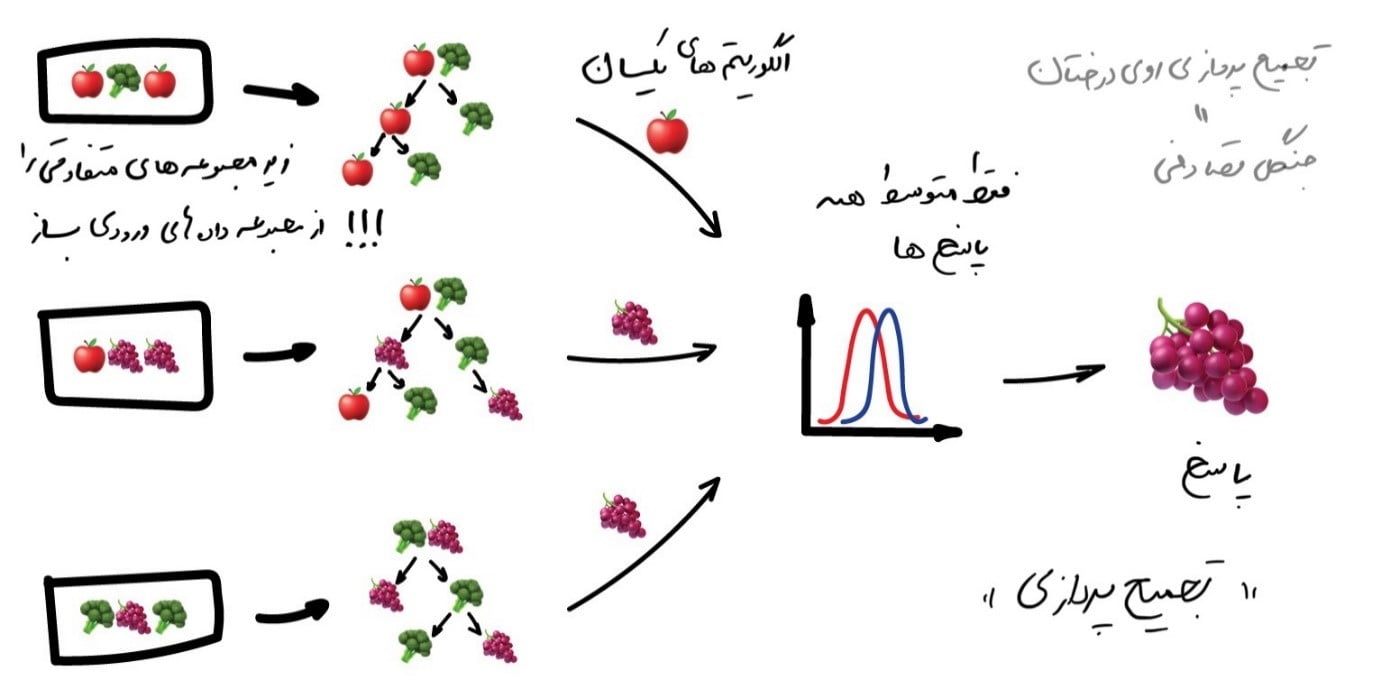
تجمیعپردازی
تجمیعپردازی یا Bagging نام مستعاری است برای Bootstrap aggregating. برای استفاده از این روش از الگوریتمهای یکسانی استفاده میشود اما آن را روی زیرمجموعههای مختلف دادههای اصلی آموزش میدهند. و در پایان فقط پاسخهای متوسط دریافت خواهید کرد.
دادهها در زیرمجموعههای تصادفی ممکن است تکرار شوند؛ به عنوان مثال از مجموعهای مانند “۱-۲-۳” میتوانیم زیرمجموعههایی مانند “۲-۲-۳″، “۱-۲-۲″، “۳-۱-۲” و غیره را دریافت کنیم. ما از این مجموعه دادههای جدید برای آموزش چندبارۀ همان الگوریتم استفاده میکنیم و سپس پاسخ نهایی را با رأی اکثریت بهصورت ساده پیشبینی میکنیم.
 معروفترین مثال تجمیعپردازی الگوریتم جنگل [dt_tooltip title=”تصادفی”]Random Forest[/dt_tooltip] است که بهسادگی روی درختهای تصمیمگیری (که در بالا نشان داده شده است) تجمیعپردازی میکند. وقتی برنامۀ دوربین گوشی خود را باز میکنید و میبینید که جعبههایی دور صورت افراد میکشد، احتمالاً این نتیجه کار الگوریتم جنگل تصادفی است. شبکههای عصبی هنوز برای اجرای بیدرنگ بسیار کند هستند، اما با توجه به اینکه میتوانند درختها را بر روی کارتهای گرافیک مدل Shader یا پردازندههای جدید و فانتزی ML محاسبه کنند، تجمیعپردازی ایدئال است.
معروفترین مثال تجمیعپردازی الگوریتم جنگل [dt_tooltip title=”تصادفی”]Random Forest[/dt_tooltip] است که بهسادگی روی درختهای تصمیمگیری (که در بالا نشان داده شده است) تجمیعپردازی میکند. وقتی برنامۀ دوربین گوشی خود را باز میکنید و میبینید که جعبههایی دور صورت افراد میکشد، احتمالاً این نتیجه کار الگوریتم جنگل تصادفی است. شبکههای عصبی هنوز برای اجرای بیدرنگ بسیار کند هستند، اما با توجه به اینکه میتوانند درختها را بر روی کارتهای گرافیک مدل Shader یا پردازندههای جدید و فانتزی ML محاسبه کنند، تجمیعپردازی ایدئال است.
برای مثال، در برخی کارها، توانایی اجرای موازی در الگوریتم جنگل تصادفی، مهمتر از کمی کاهش دقتی است که نسبت به روشهای تقویتی(Boosting) دارد. بهخصوص در پردازش بلادرنگ و بیفاصله؛ همیشه باید روشهای مختلف را سبک و سنگین کرد.
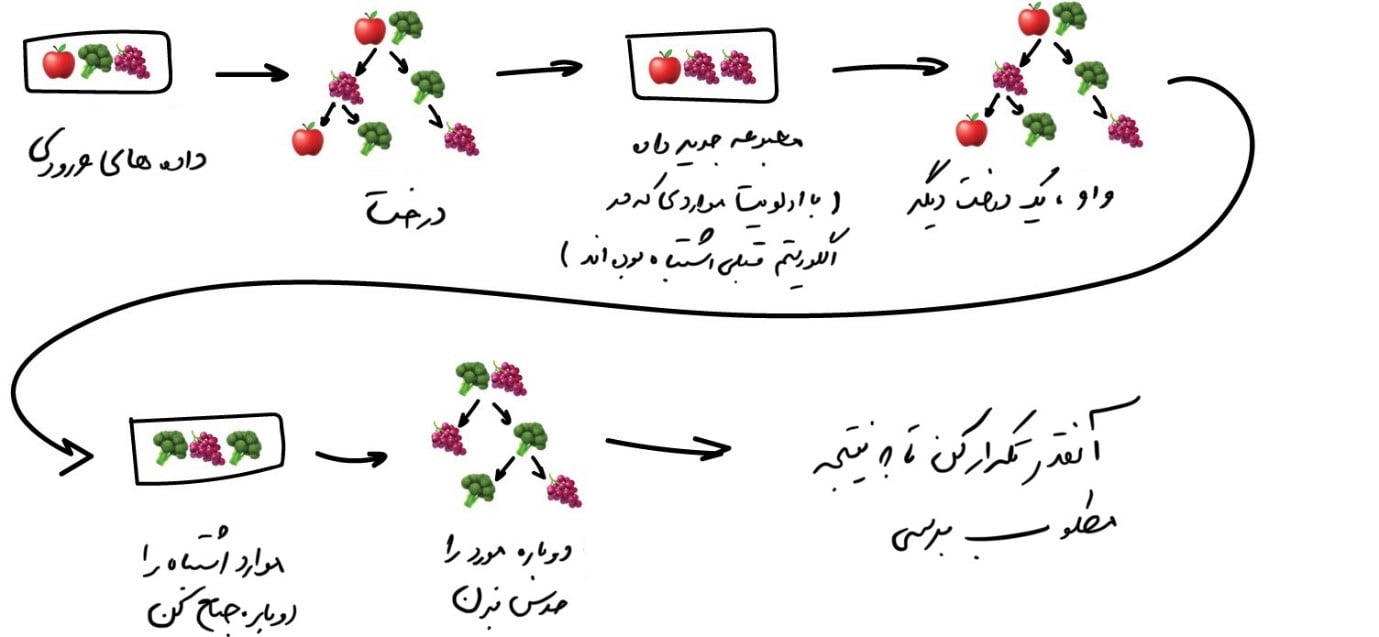
تقویت
الگوریتمهای تقویت بهصورت متوالی و یکبهیک آموزش داده میشوند. هر مورد بیشترین توجه خود را به نقاط دادهای میکند که توسط مورد قبلی اشتباه پیشبینی شده بوده است. در یک جمله میتوان گفت تقویت یعنی: آنقدر تکرار کنید تا بالاخره خوشحال شوید.
در تقویت نیز مانند تجمیعپردازی، از زیرمجموعههایی از دادههای خود استفاده میکنیم. اما این بار آنها بهطور تصادفی تولید نمیشوند. اکنون، در هر نمونۀ فرعی، بخشی از دادههایی را میگیریم که الگوریتم قبلی نتوانسته آن را پردازش کند. بنابراین، ما یک الگوریتم جدید ایجاد میکنیم که یاد بگیرد خطاهای قبلی را برطرف کند.
 مزیت اصلی در اینجا، دقت بسیار بالای طبقهبندی است و مضرات آن نیز همانطور که قبلاً گفته شده عدم امکان موازیشدن است. اما هنوز هم سریعتر از شبکههای عصبی کار میکند. مثل مسابقه بین کمپرسی و ماشین مسابقه است. کامیون میتواند کارهای بیشتری انجام دهد، اما اگر میخواهید سریع بروید، یک ماشین بگیرید!
مزیت اصلی در اینجا، دقت بسیار بالای طبقهبندی است و مضرات آن نیز همانطور که قبلاً گفته شده عدم امکان موازیشدن است. اما هنوز هم سریعتر از شبکههای عصبی کار میکند. مثل مسابقه بین کمپرسی و ماشین مسابقه است. کامیون میتواند کارهای بیشتری انجام دهد، اما اگر میخواهید سریع بروید، یک ماشین بگیرید!
اگر میخواهید یک نمونۀ واقعی از تقویت را داشته باشید، فیسبوک یا گوگل را باز کنید و شروع به تایپ کردن یک عبارت جستجو کنید. آیا میتوانید صدای لشگری از درختان را بشنوید که غرش میکنند و در هم میکوبند تا نتایج را بر اساس ارتباط مرتب کنند؟ این صدا بهاین خاطر است که آنها از تقویت استفاده میکنند!
| امروزه سه ابزار محبوب برای تقویت وجود دارد، می توانید گزارش مقایسهای را در CatBoost vs. LightGBM vs. XGBoost بخوانید. |
بخش چهارم: شبکههای عصبی و یادگیری عمیق
“ما یک شبکۀ هزارلایه و دهها کارت گرافیک داریم، اما هنوز نمیدانیم کجا از آن استفاده کنیم. بیایید عکسهای گربه تولید کنیم!”
امروزه از شبکههای عصبی برای موارد زیر استفاده میشود:
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]
- جایگزینی همۀ الگوریتمهایی که در فصول قبل به آن اشاره شد.
- شناسایی اشیاء در عکسها و فیلمها
- تشخیص و ترکیب گفتار
- پردازش تصویر، انتقال سبک
- ترجمۀ ماشینی
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5494″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
معماریهای محبوب:[dt_tooltip title=”پرسپترون”] Perceptron[/dt_tooltip]،[dt_tooltip title=”شبکۀ پیچشی”] Convolutional Network[/dt_tooltip](CNN)،[dt_tooltip title=”شبکههای بازگشتی”] Recurrent Networks [/dt_tooltip](RNN)، [dt_tooltip title=”رمزنگارهای خودکار”] Autoencoders[/dt_tooltip]
اگر هیچکس تا بهحال شبکههای عصبی را با استفاده از تشبیهات “مغز انسان” برای شما توضیح نداده است، خوشحال باشید! ابتدا اجازه دهید آنطور که دوست دارم توضیح دهم:
هر شبکۀ عصبی اساساً مجموعهای از [dt_tooltip title=”نورونها و ارتباطات بین آنهاست. نورون“]Neuron[/dt_tooltip] تابعی است با یک دسته از ورودیها و یک خروجی. وظیفۀ آن این است که تمام اعداد را از ورودی خود گرفته، تابعی را روی آنها اعمال کند و نتیجه را به خروجی ارسال کند.
در اینجا مثالی از یک نورون ساده اما مفید در زندگی واقعی آورده شده است: همۀ اعداد را از ورودیها جمع کنید و اگر این مجموع بزرگتر از N باشد، نتیجۀ یک و در غیر اینصورت، نتیجۀ صفر را ارائه دهید.
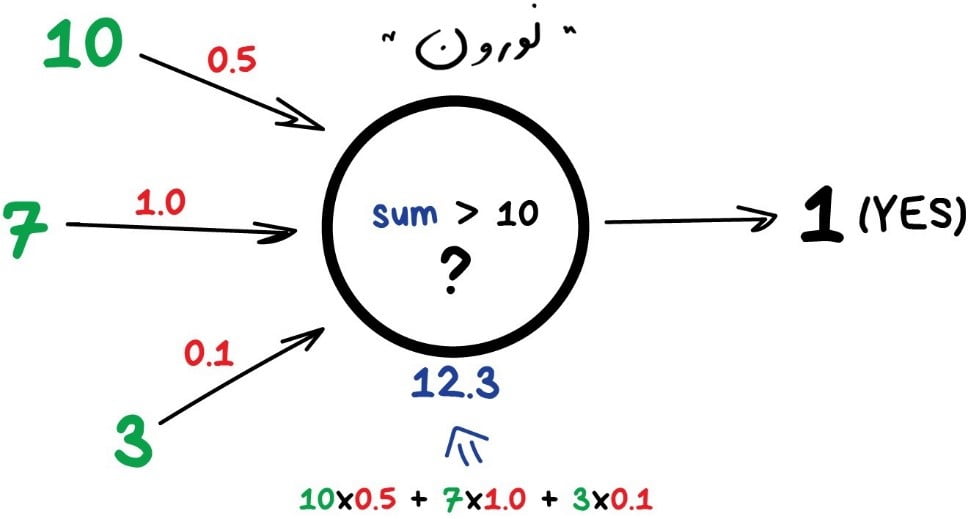
[dt_tooltip title=”ارتباطات“]Connections[/dt_tooltip] مانند کانالهای بین نورونها هستند. آنها خروجیهای یک نورون را به ورودیهای نورون دیگر متّصل میکنند تا بتوانند ارقام را برای یکدیگر ارسال کنند. هر اتصال فقط یک پارامتر دارد: وزن. این وزن مانند قدرت اتصال برای سیگنال است. وقتی عدد ۱۰ از یک اتصال با وزن ۰.۵ عبور میکند به ۵ تبدیل میشود.
این وزن ها به نورون میگویند که به یک ورودی بیشتر و به ورودی دیگر کمتر پاسخ دهد. وزنها هنگام تمرین و آموزش تنظیم میشوند، در اصل شبکه اینگونه یاد میگیرد. این تقریباً اساس شبکههای عصبی است.
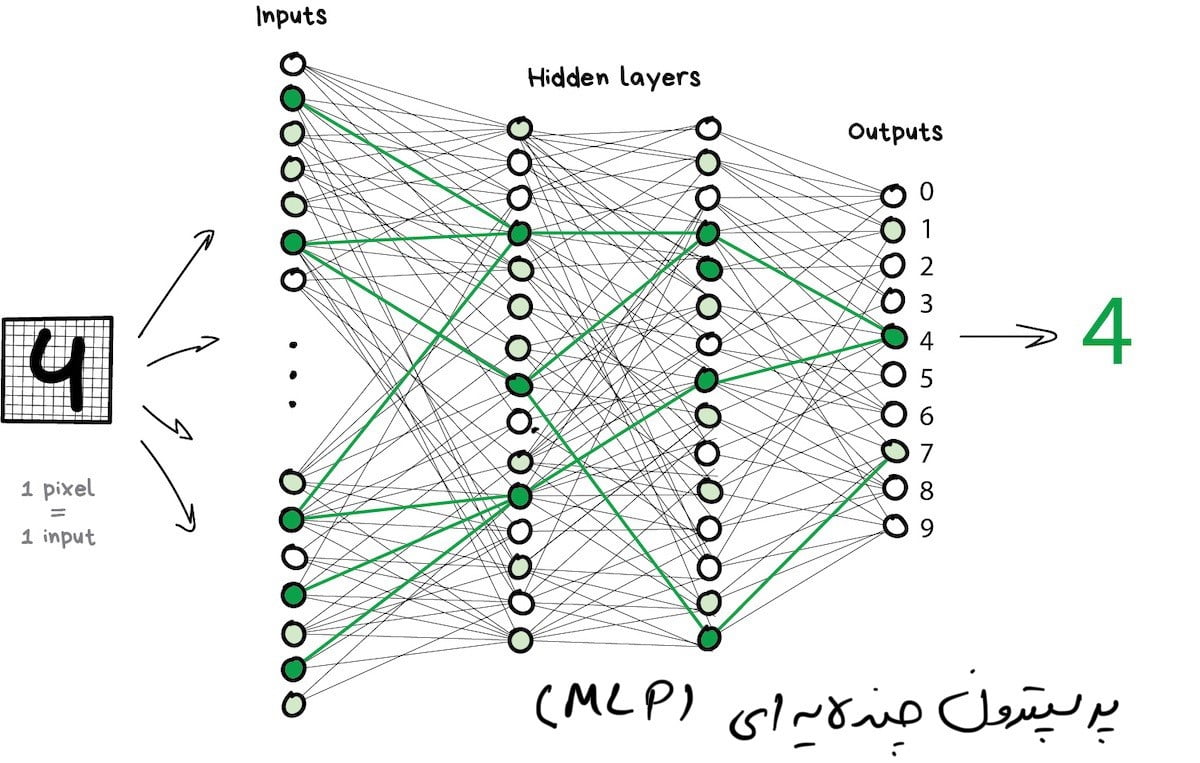
برای جلوگیری از درافتادن شبکه در هرج و مرج، نورونها بهجای اتّصال بهصورت تصادفی، توسط لایهها به هم متّصل میشوند. درون یک لایه، نورونها به هم متّصل نیستند، اما به نورونهای لایههای بعدی و قبلی متصل هستند. دادهها در شبکه دقیقاً در یک جهت حرکت میکنند: از ورودیهای اولین لایه تا خروجیهای آخرین لایه.
اگر بهتعداد کافی لایه ایجاد کنید و وزنها را بهدرستی تنظیم نمایید، موارد زیر را بهدست خواهید آورد: با اعمال تابع نورونها روی ورودی، نورونهای لایههای بعدی فعال میشوند. بهعنوان مثال، در تصویر دستنویس رقم ۴، پیکسلهای سیاه نورونهای مرتبط را فعال میکنند، و بههمین ترتیب تا زمانی که در نهایت خروجی عدد ۴ را روشن کند ادامه مییابد.
در حین برنامهنویسی واقعی، هیچکس نورونها و ارتباطات را نمینویسد. در عوض، همهچیز بهشکل ماتریس نشان داده میشود و برای عملکرد بهتر، محاسبات مربوطه براساس ضرب ماتریس انجام میشود. در ویدیویی که آدرس آن در ادامه آمده است، این مورد و نتیجۀ آن بهخوبی نشان داده شده و کل فرآیند بهروشی آسان و قابلهضم با استفاده از مثال تشریح شده است. اگر میخواهید این مفهوم شبکۀ عصبی را بفهمید، حتماً این ویدئو را تماشا کنید.
| شبکۀ عصبی چیست؟ | |
| https://www.youtube.com/embed/aircAruvnKk |
| شبکهای که دارای چندین لایه است که بین هر نورون ارتباط برقرار میکند، پرسپترون (MLP) نامیده میشود و سادهترین معماری است که برای یک تازه کار در نظر گرفته میشود. معمولا در عمل از این معماری برای حل مسائل استفاده نمیشود. |
پس از ساختن یک شبکه، وظیفۀ اصلی ما تعیین راههای مناسبی است تا نورونها به سیگنالهای دریافتی واکنش درستی نشان دهند. باید یادمان باشد که دادههایی داریم که شامل نمونههایی از «ورودی» و «خروجی» مناسب هستند. ما نقشهای از همان رقم ۴ را به شبکۀ خود ارائه میدهیم و به آن میگوییم “وزنهای خود را بهگونهای تطبیق دهید که هر زمان این ورودی را مشاهده کردید، خروجی باید عدد ۴ را منتشر کند”.
برای شروع، تمام وزنها بهصورت تصادفی اختصاص داده میشوند. پس از اینکه یک رقم به آن دادیم، یک پاسخ تصادفی صادر میشود زیرا وزنها هنوز درست تنظیم نشدهاند، و بعد مقایسه میکنیم که این نتیجه چقدر با نتیجۀ درست تفاوت دارد. سپس شروع
میکنیم و از خروجی شبکه به عقب برمیگردیم(به سمت ورودی) و به هر نورون میگوییم: “هی! تو اینجا فعال شدی اما کار وحشتناکی انجام دادی و همه چیز از اینجا به انحراف رفته است، باید کمتر به این اتصال و بیشتر به آنیکی توجه کنیم، قبول؟”.
پس از صدها هزار چرخۀ «[dt_tooltip title=”استنتاج-بررسی-تنبیه”]infer-check-punish[/dt_tooltip]» این امید وجود دارد که اوزان تصحیح شوند و طبق خواستۀ ما عمل کنند. نام علمی این رویکرد[dt_tooltip title=”انتشار پسگرد“]Backpropagation[/dt_tooltip] یا “روش انتشار پسگرد یک خطا” است. جالب است که بیست سال طول کشید تا این روش کشف شود. قبل از این ما بهنوعی دیگر شبکههای عصبی را آموزش میدادیم.
دومین ویدیوی مورد علاقۀ من در این فصل، این فرآیند را به طور عمیقتر توصیف میکند، و هنوز هم بسیار مورد استفاده است.
| چگونه شبکۀ عصبی یاد میگیرد؟ | |
| https://www.youtube.com/embed/IHZwWFHWa-w |
یک شبکۀ عصبی که خوب آموزش دیده باشد، میتواند کار هر یک از الگوریتمهایی که در این مقاله به آن اشاره شده است را انجام دهد(و اغلب با دقت بیشتری کار میکند). پدیدۀ جهانیشدن باعث شده است که این رویکردها بهطور گستردهای محبوب شوند. در نهایت، ما یک معماری از مغز انسان داریم، که به ما میگوید فقط باید لایههای زیادی را گرد هم آوریم و هر دادۀ ممکنی را که به درد آن لایهها میخورد فراهم کرده و به آنها آموزش دهیم. با این اوصاف اولین زمستان هوش مصنوعی شروع شد، و سپس برفها آب شد و موج دیگری از ناامیدی بهراه افتاد. چرا؟
معلوم شد که شبکههایی که تعداد زیادی لایه دارند، به قدرت محاسباتی غیرقابل تصوری نیاز دارند.(البته در آن زمان! چون امروزه یک رایانۀ شخصی مخصوص بازیها که به کارتهای geforce مجهز شده باشد، از دیتاسنترهای آن زمان بهتر عمل میکند). بنابراین مردم در آن زمان هیچ امیدی به کسب قدرت محاسباتی مورد نیاز نداشتند و شبکههای عصبی یک مشکل بزرگ بودند.
اما از ده سال پیش یادگیری عمیق دوباره گسترش یافت.
| یک جدول زمانی خوبی از یادگیری ماشین وجود دارد که فراز و فرود امیدها و امواج بدبینی را به خوبی توصیف می کند. |
در سال ۲۰۱۲، شبکههای عصبی پیچشی به پیروزی چشمگیری در رقابت با ImageNet دست یافتند که باعث شد جهان بهطور ناگهانی روشهای یادگیری عمیق که در دهه ۹۰ مطرح شده بود را دوباره به یاد بیاورد. حالا ما کارت گرافیک داریم!
تفاوتهای یادگیری عمیق با شبکههای عصبی کلاسیک، در روشهای آموزشی جدید بود که میتوانست شبکههای بزرگتر را مدیریت کند. امروزه نظریهها سعی میکنند یادگیری را به دو دستۀ عمیق و نهچندانعمیق تقسیم کنند. و ما بهعنوان تمرینکنندگان، حتی زمانی که میخواهیم یک شبکۀ کوچک با پنج لایه بسازیم، از کتابخانههای محبوب «عمیق» مانند Keras، TensorFlow و PyTorch استفاده میکنیم. فقط بهاین دلیل که از همۀ ابزارهای قبلی مناسبتر است. حالا دیگر همۀ آنها را شبکههای عصبی مینامیم.
در اینجا در مورد دو نوع اصلی صحبت خواهیم کرد: CNN و RNN
شبکههای عصبی پیچشی (CNN)
شبکههای عصبی پیچشی در حال حاضر همهگیر شدهاند. این شبکهها برای جستجوی اشیاء روی عکسها و فیلمها، تشخیص چهره، انتقال سبک نقاشی، تولید و بهبود تصاویر، ایجاد جلوههایی مانند حرکت آهسته و بهبود کیفیت تصویر استفاده میشوند. امروزه CNN در تمام مواردی که شامل عکس و فیلم است استفاده میشود. حتی در آیفون شما، عکسهای شما را از چندین مورد از این شبکهها میگذارند تا اشیاء مختلف را در آن شناسایی کنند. البته اگر چیزی برای تشخیص وجود داشته باشد!

| تصویر بالا نتیجهای است که توسط Detectron تهیه شده است که اخیراً کد آن توسط فیسبوک منبع باز شده است. |
مشکلی که در تصاویر وجود داشت، مشکل استخراج ویژگیها از آنها بود. متن را بر اساس جملات، دامنۀ کلمات تخصصی و … میتوان تقسیم کرد. اما تصاویر باید بهصورت دستی برچسبگذاری میشدند تا به دستگاه آموزش داده شود تا مثلاً بفهمیم گوشها یا دمهای گربه در یک تصویر خاص کجا هستند. این رویکرد نام “[dt_tooltip title=”ویژگیهای کار دستی”]handcrafting features[/dt_tooltip]” را گرفت و تقریباً توسط همه استفاده میشد.
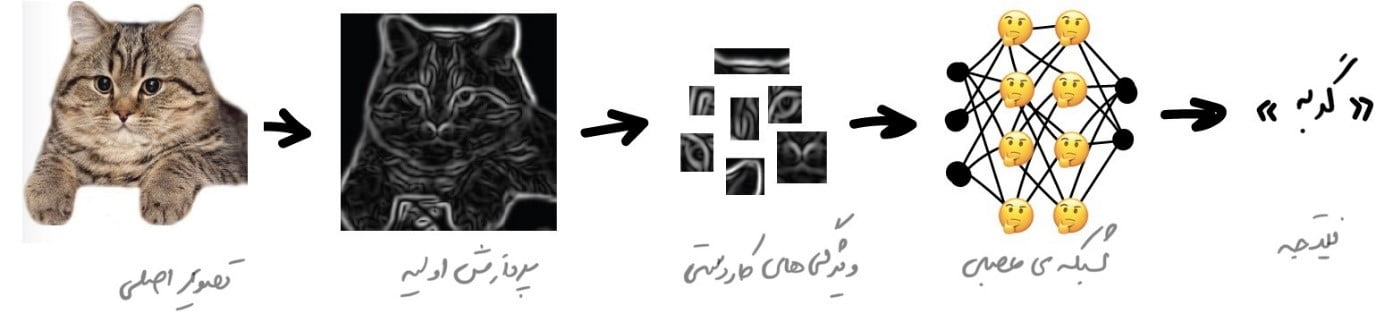
مشکلات زیادی در کار دستی وجود دارد.
اول از همه، اگر گربهای گوشهایش را پایین انداخته یا از دوربین دور شده باشد، به مشکل میخوریم چون شبکۀ عصبی چیزی را نمیبیند.
ثانیاً، اگر بخواهیم ۱۰ ویژگی مختلف را که گربهها را از حیوانات دیگر متمایز میکند، لیست کنیم کار سختی است. من نمیتوانم این کار را انجام دهم اما وقتی شبها یک لکۀ سیاه را میبینم که با عجله از کنارم رد میشود، حتی اگر آن را فقط در گوشۀ چشمم
ببینم، قطعاً گربه را از موش تشخیص میدهم. از آنجا که مردم فقط به شکل گوش یا تعداد پاها نگاه نمیکنند و بسیاری از ویژگیهای مختلف را در نظر میگیرند که حتی به آنها فکر نمیکنند، بنابراین توضیح این ویژگیها به ماشین غیر ممکن است.
این شرایط به این معنی است که ماشین باید چنین ویژگیهایی را که بر روی خطوط اصلی قرار میگیرند به تنهایی یاد بگیرد. ما کارهای زیر را انجام میدهیم:
ابتدا کل تصویر را به بلوکهای پیکسل ۸*۸ تقسیم میکنیم و به هر کدام یک نوع خط غالب اختصاص میدهیم: مثلاً افقی [-]، عمودی [|] یا یکی از موربها [/]. از طرف دیگر ممکن است چندین حالت دیگر نیز به دفعات قابل مشاهده باشند که ما از قبل پیشبینی نکرده باشیم، و از اینرو نمیتوانیم همیشه کاملاً مطمئن باشیم.
خروجی میتواند چندین جدول از تکهها باشد که در واقع سادهترین ویژگیهایی هستند که لبههای اشیاء را در تصویر نشان میدهند. این تکهها خودشان بهتنهایی تصویر هستند اما از تکههای دیگری ساخته شدهاند. بنابراین میتوانیم یک بار دیگر یک بلوک ۸×۸ را برداریم و ببینیم که چگونه با هم مطابقت دارند. و دوباره و دوباره…
این عملیات، پیچش نامیده میشود که نام این روش را به آن داده است. پیچیدگی را میتوان به عنوان لایهای در یک شبکه عصبی نشان داد، زیرا هر نورون میتواند هر تابعی داشته باشد.
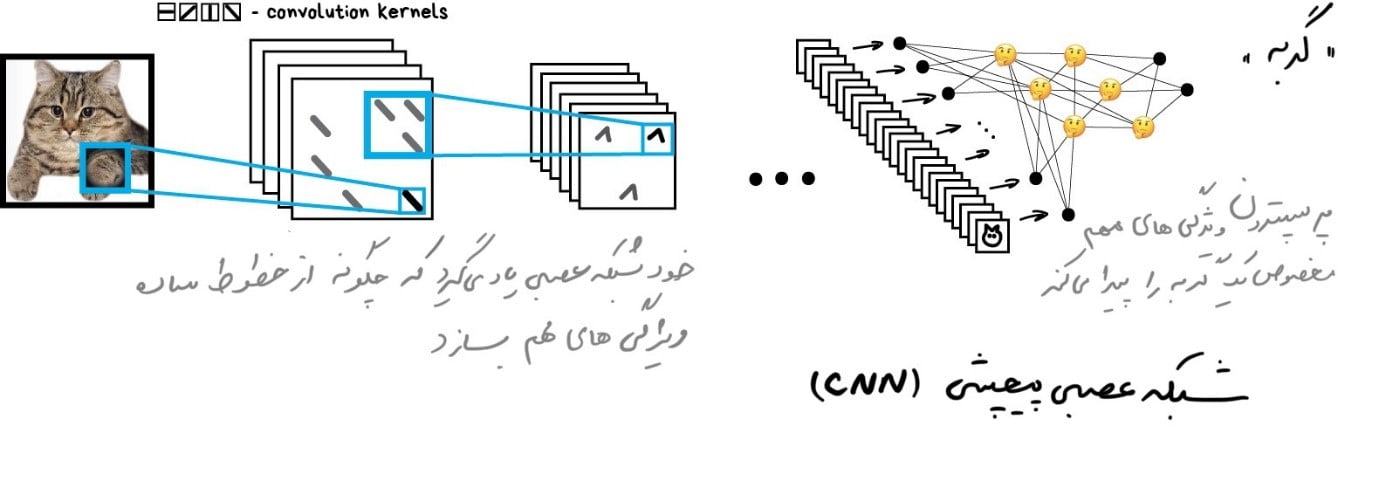
هنگامی که شبکۀ عصبی خود را با تعداد زیادی عکس از گربهها تغذیه میکنیم، شبکه بهطور خودکار وزنهای بزرگتری را به ترکیبی از تکههایی که اغلب دیده است اختصاص میدهد. فرقی نمیکند که یک خط مستقیم پشت گربه باشد یا یک جسم پیچیدۀ هندسی مانند صورت گربه! این شبکه بسیار فعال خواهد بود.
در خروجی شبکه، یک پرسپترون ساده قرار میدهیم که فعالترین ترکیبها را بررسی میکند و بر اساس آن گربهها را از سگها متمایز میکند.
[vc_row][vc_column][vc_row_inner][vc_column_inner width=”2/3″][vc_column_text]زیبایی این ایده این است که ما یک شبکۀ عصبی داریم که بهتنهایی متمایزترین ویژگیهای اشیاء را جستجو میکند. ما نیازی به انتخاب دستی آنها نداریم. ما میتوانیم با جستجوی میلیاردها تصویر، هر مقدار از تصویر هر شیء را به آن بدهیم و شبکۀ ما نقشههای ویژگی را از تکههای آنها ایجاد نموده و یاد میگیرد که هر شیء را بهتنهایی متمایز کند.
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/3″][vc_single_image image=”5505″ img_size=”full” alignment=”center”][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row]
برای این موضوع من یک لطیفۀ بیمزۀ مفید درست کردهام:
به شبکۀ عصبی خود ماهی بدهید و تا آخر عمر قادر به تشخیص ماهی خواهد بود. به شبکه عصبی خود یک میلۀ ماهیگیری بدهید و تا آخر عمر می تواند میلههای ماهیگیری را تشخیص دهد…
| شبکههای عصبی در تلاش برای صحبت هستند. | |
| https://www.youtube.com/embed/NG-LATBZNBs |
شبکههای عصبی بازگشتی(RNN)
دومین معماری محبوب امروزی شبکههای بازگشتی هستند که کاربردهای مفیدی مانند ترجمۀ [dt_tooltip title=”ماشین عصبی”]
مطلب نویسنده مقاله را در این مورد میتوانید در آدرس زیر مطالعه نمائید.:
https://vas3k.com/blog/machine_translation/[/dt_tooltip]، تشخیص گفتار و سنتز صدا در دستیارهای هوشمند را ارائه دادهاند. RNNها برای دادههای متوالی مانند صدا، متن یا موسیقی بهترین هستند.
آیا [dt_tooltip title=”Sam”]مایکروسافت سام، یک نرمافزار تبدیل متن به گفتار محصول شرکت مایکروسافت بود که همراه ویندوز XP عرضه شد و در ویندوز ۲۰۰۰ نیز گنجانده شده است، اما الگوهای گفتاری او متفاوت است. سام یک ترکیبکننده گفتار است که به دلیل ظاهر شدن در صدها ویدیوی YouTube که در آنها آواز میخواند، خطاها و علامتها را میخواند، صداگذاری میکند، بازی میکند، لوگو را هدایت میکند، معروف و … معروف شده است.[/dt_tooltip] محصول مایکروسافت(تبدیلکنندۀ متن به گفتار برای مدرسه) در ویندوز XP را به خاطر دارید؟ آن پسر بامزه کلمات را حرف به حرف میسازد و سعی میکند آنها را به هم بچسباند. اکنون به Amazon Alexa یا Assistant از گوگل نگاه کنید. آنها نه تنها کلمات را به وضوح بیان میکنند، بلکه لهجههای مناسب را نیز قرار میدهند!
همۀ اینها بهاین دلیل است که دستیارهای صوتی مدرن، طوری آموزش داده شدهاند که نه حرفبهحرف، بلکه یک عبارات را به صورت کامل ادا کنند. ما میتوانیم مجموعهای از متون صوتی را انتخاب کنیم و یک شبکۀ عصبی را آموزش دهیم تا نزدیکترین دنبالۀ صوتی به گفتار اصلی را تولید کند.
بهعبارت دیگر، از متن بهعنوان ورودی و از صدای آن بهعنوان خروجی مورد نظر استفاده میکنیم. ما از یک شبکۀ عصبی میخواهیم تا مقداری صدا برای متنِ دادهشده تولید کند، سپس آن را با خطاهای اصلی و تصحیح آنها مقایسه کرده و سعی کند تا حد امکان به ایدئال نزدیک شود.
این یک فرآیند یادگیری کلاسیک است و حتی یک پرسپترون برای این کار کافی است. اما چگونه باید خروجیهای آن را تعریف کنیم؟ ایجاد یک خروجی خاص برای هر عبارت ممکن، یک انتخاب نیست بلکه بدیهی است.یعنی حتماً باید در ازای هر عبارت یک خروجی صوتی داشته باشد.
در اینجا، این واقعیت که متن، گفتار یا موسیقی همگی «دنباله» هستند به ما کمک میکند. آنها از واحدهای متوالی مانند هجا تشکیل شدهاند. همۀ آنها منحصربهفرد بهنظر میرسند اما به موارد قبلی بستگی دارند و بسته بهآنها تغییر میکند. اگر این ارتباط را از دست بدهید دچار لکنت و اعوجاج میشوید.
ما میتوانیم پرسپترون را برای تولید این صداهای منحصر به فرد آموزش دهیم. اما سوالی که پیش میآید این است که چگونه پاسخ های قبلی را به خاطر میآورد؟ در اینجا یک ایده اضافهکردن حافظه به هر نورون و استفاده از آن بهعنوان ورودی اضافی در اجرای بعدی است. یک نورون میتواند برای خودش یادداشت بسازد! بههمین سادگی! فرض کنید در یک کلمه، یک حرف صدادار داشته باشیم، صدای بعدی باید بلندتر باشد (و این یک مثال بسیار ساده است).
اینگونه بود که شبکههای بازگشتی ظاهر شدند.
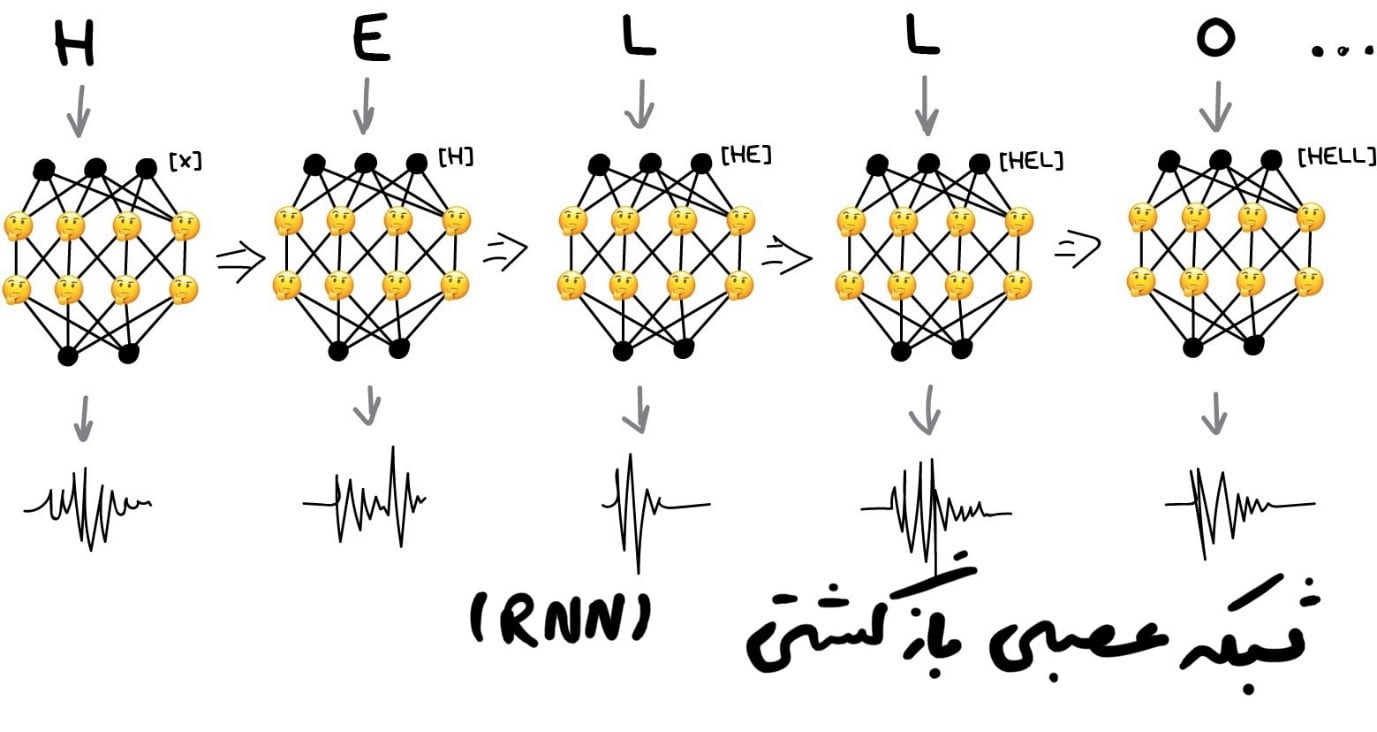
این رویکرد یک مشکل بزرگ داشت: وقتی همۀ نورونها نتایج گذشتۀ خود را به یاد آوردند، تعداد ارتباطات در شبکه آنقدر زیاد شد که از نظر فنی تنظیم همۀ وزنها غیرممکن بود.
وقتی یک شبکۀ عصبی نمیتواند فراموش کند، نمیتواند چیزهای جدیدی یاد بگیرد (که البته انسانها هم همین عیب را دارند).
اولین تصمیم ساده بود: حافظۀ نورون را محدود کنید. فرض کنید، بیش از ۵ نتیجۀ اخیر را حفظ نکنید. اما این تصمیم کلِ ایده را بههم میزد.
رویکرد بسیار بهتری بعداً ایجاد شد: استفاده از سلولهای ویژه، شبیه به حافظۀ رایانه. هر سلول میتواند یک عدد را ضبط کند، آن را بخواند یا آن را بازنشانی کند. آنها سلولهای حافظۀ بلندمدت و[dt_tooltip title=” کوتاهمدت(LSTM)”]Long and short-term memory[/dt_tooltip] نامیده میشدند.
اکنون، زمانی که یک نورون نیاز به تنظیم یادآوری دارد، یک پرچم در آن سلول قرار میدهد. مانند “در کلمه یک حرف بیصدا بود، دفعۀ بعد از قواعد تلفّظِ متفاوت استفاده کن!”. هنگامی که پرچم دیگر مورد نیاز نیست، سلولها بازنشانی میشوند و تنها ارتباطات “دراز مدت” پرسپترون کلاسیک باقی میمانند. بهعبارت دیگر، شبکه تنها برای یادگیری وزنها بلکه برای تنظیم این یادآورها نیز آموزش دیده است.
ساده است، اما کار میکند!
| CNN + RNN = Fake Obama | |
| https://www.youtube.com/embed/cQ54GDm1eL0 |
میتوانید از هر کجا نمونۀ گفتار بگیرید. برای مثال، BuzzFeed سخنرانیهای اوباما را در نظر گرفت و شبکه عصبی را برای تقلید صدای او آموزش داد. همانطور که می بینید، سنتز صدا در حال حاضر یک کار ساده است. ویدیو هنوز مشکل دارد، اما مسئله زمان است.
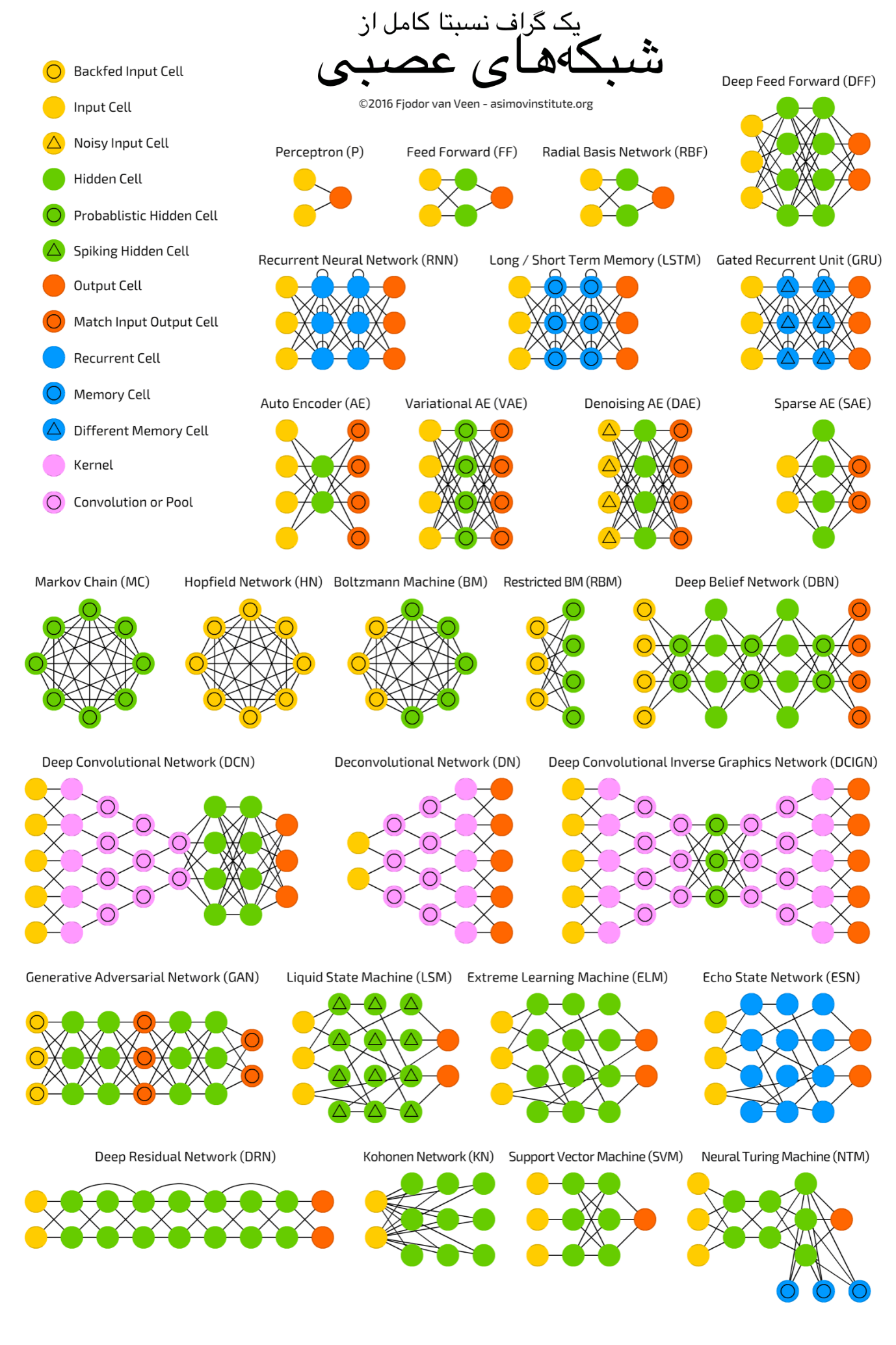
معماریهای شبکهی بسیار بیشتری در طبیعت وجود دارد. من یک مقالۀ خوب بهنام Neural Network Zoo را پیشنهاد میکنم که تقریباً همۀ انواع شبکههای عصبی در آن جمعآوری شده و بهطور خلاصه توضیح داده شده است.
 بخش پایانی: چه زمانی با ماشینها وارد جنگ میشویم؟
بخش پایانی: چه زمانی با ماشینها وارد جنگ میشویم؟
 بخش پایانی: چه زمانی با ماشینها وارد جنگ میشویم؟
بخش پایانی: چه زمانی با ماشینها وارد جنگ میشویم؟مشکل اصلی اینجاست که این سوال مطرح می شود که “چهزمانی ماشینها از ما باهوشتر میشوند و همۀ را به بردگی میکشند؟” این سوال در ابتدا اشتباه است چرا که شرایط ناشناخته و پنهان بیش از حدی در آن وجود دارد.
وقتی ما میگوییم: «از ما باهوشتر شو»، مثل اینکه در ذهنمان ابعاد منسجم و مشخصی از هوش وجود دارد. که بالاترین آن یک انسان است، سگها کمی پایینتر هستند و کبوترهای احمق در همان پایین آویزان هستند.
و این مشخصاً اشتباه است!
اگر اینطور بود، هر انسانی باید در همهچیز حیوانات را شکست میداد، اما اینگونه نیست. یک سنجابِ معمولی میتواند هزار مکان پنهان را با آجیل بهیاد بیاورد در حالیکه من حتی نمیتوانم بهیاد بیاورم که کلیدهایم کجا هستند!
پس یا هوش مجموعهای از مهارتهای مختلف است(نه یک ارزش واحد قابل اندازهگیری)، یا به خاطر سپردن مکانهای ذخیرهشدنِ آجیل در زمرۀ هوش قرار نگرفته است!
یک سوال جالبتر برای من: چرا ما معتقدیم که امکانات مغز انسان محدود است؟ نمودارهای پرطرفدار زیادی در اینترنت وجود دارد که در آن پیشرفت فناوری به صورت نمائی ترسیم شده است ولی امکانات انسانی ثابت است. اما آیا اینطور است؟
خوب، ۱۶۸۰ را در ۹۵۰ در ذهن خود ضرب کنید. من میدانم که شما حتی تلاش نمیکنید، اما اگر یک ماشین حساب به شما بدهند، این کار را ظرف دو ثانیه انجام خواهید داد. پس قبول دارید که ماشین حساب، قابلیتهای مغز شما را گسترش داده است؟
اگر بله، آیا می توانم به گسترش مغز با ماشینهای دیگر ادامه دهم؟ مثلاً از یادداشتهایی در تلفنم استفاده کنم تا حجم زیادی از دادهها را به خاطر نیاورم؟ (که بهنظر میرسد که من در حال انجام آن هستم). من تواناییهای مغزم را با ماشینها گسترش میدهم.
در اینباره بیشتر فکر کنید و ممنون که این متن را خواندید.
